Understanding Statistical Regularity Through Random Walks | Cheenta Probability Series
 Join Trial or Access Free ResourcesJoin Trial or Access Free Resources
Join Trial or Access Free ResourcesJoin Trial or Access Free ResourcesThis is another blog of the Cheenta Probability Series. Let's give a formal definition of statistical regularity to bring some seriousness into account.
**10 min read**
“The Law of Statistical Regularity formulated in the mathematical theory of probability lays down that a moderately large number of items chosen at random from a very large group are almost sure to have the characteristics of the large group.” ~ W.I.King
So, let's give a formal definition of this to bring some seriousness into account. If a sequence of independent experiments is held under the same specified conditions, the proportion of occurrences of a given event stabilize as the number of experiments becomes larger. This is ideally what is known to be statistical regularity.
It is an umbrella term that covers the law of large numbers, all central limit theorems and ergodic theorems.
But keeping in mind that we cover stuff for undergraduates mainly,we would not get into the aforementioned topics.
Richard Von Mises first mathematically demonstrated the idea of statistical regularity by pinpointing that no method for forming a subsequence of a random sequence (an infinite sequence of 0's and 1's) improves the odds for a specific event.
For instance, a sequence of fair coin tosses produces equal and independent 50/50 chances for heads and tails. A simple system of betting on heads every 3rd, 7th, or 21st toss, etc., does not change the odds of winning in the long run.
This is famously known as the "Impossibility of a gambling system".
This is in itself a topic in advanced probability theory and stochastic processes , but I will try to keep it simple here. Let's consider a game in which a player starts at the point \( x=0 \) and at each move, is required to take a step either forward (toward \(+x\) ) or backward (toward \(−x\)). The choice is to be made randomly (maybe by tossing a coin). How shall we describe the resulting motion? In general, this problem is closely related to the coin tossing problem.
First let us look at a few examples of a random walk. We may characterize the walker’s progress by the net distance \(D_N \) traveled in N steps. We illustrate the graph of the random walker in three instances below:
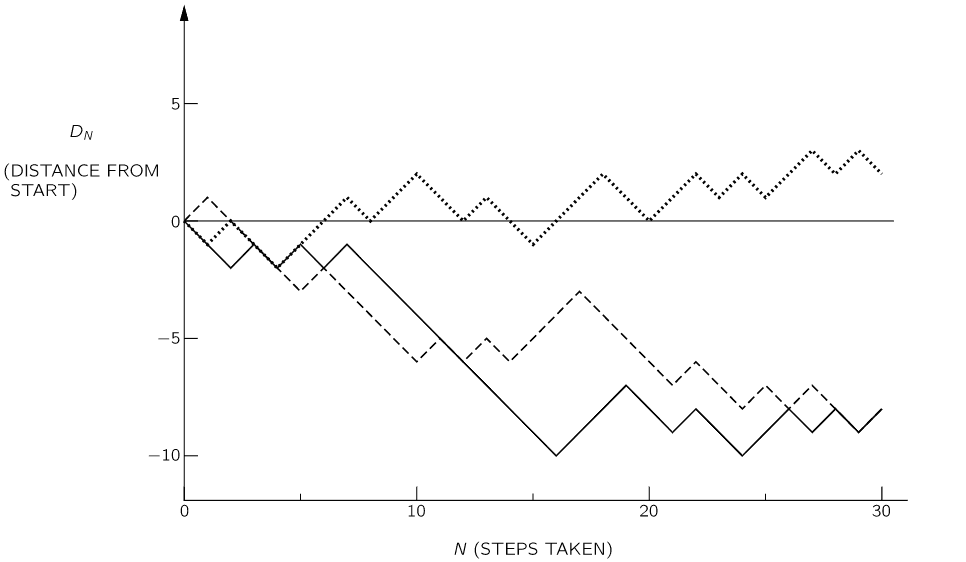
What can we say about such a motion? We might first ask: “How far does he get on the average?” We must expect that his average progress will be zero, since he is equally likely to go either forward or backward. But we have the feeling that as \( N \) increases, he is more likely to have strayed farther from the starting point. We might, therefore, ask what is his average distance travelled in absolute value, that is, what is the average of \(|D|\). It is, however, more convenient to deal with another measure of “progress,” the square of the distance:\( D^2 \) is positive for either positive or negative motion, and is therefore a reasonable measure of such random wandering.
Now, till now we have not defined expected value of a quantity or a variable, which we sure will in the upcoming blog posts. For now , by “expected value” we mean the probable value (our best guess), which we can think of as the expected average behavior in many repeated sequences.
We represent such an expected value by \( ⟨D_N ^2⟩ \), and may refer to it also as the “mean square distance.” After one step, \( D^2 \) is always \( +1 \), so we have certainly \( ⟨D_1 ^2⟩=1 \).
Now , we have an obvious recursion between \(D_N\) and \(D_{N-1} \). More specifically, \(D_N = D_{N-1} +1 \) or \(D_N=D_{N-1}-1 \).
Thus, squaring, \(D_N ^2 = D_{N-1} ^2 + 2 D_{N-1}+1 \) or, \(D_N^2 = D_{N-1} ^2 - 2 D_{N-1}+1 \)
In a number of independent sequences, we expect to obtain each value one-half of the time, so our average expectation is just the average of the two possible values. The expected value of \(D_N ^2 \) is \(D_{N−1} ^2+1 \) . In general, we should expect for \(D_{N−1} ^2 \) its “expected value” \( ⟨D_{N−1} ^2 ⟩ \) (by definition!). So \( ⟨D_N ^2⟩=⟨D_{N−1} ^2 ⟩+1 \).
We have already seen that \(⟨D_1 ^2⟩=1\); it follows then that \( ⟨D_N ^2 ⟩=N \).
Damn, that was easy. Pretty simple right?
Now let's draw an analogy of this game with a simple coin tossing experiment ( which many authors use as the prototype for demonstrating regularity !). Yeah, we were thinking slightly in an unorthodox manner ;).
To appropriately represent drifting away from the origin, in a random walk, we can use the Root Mean Square distance:
\( D_R = \sqrt{ ⟨D ^2⟩ } =\sqrt{N} \).
If we imagine the direction of each step to be in correspondence with the appearance of heads or tails in a coin toss, then \( D = N_H−N_T \) , the difference in the number of heads and tails. Since \( N_H+N_T=N \), the total number of steps (and tosses), we have \( D=2N_H−N \).
Now, it's time to merge our intuition into reality. If the coin is honest or fair, what do you expect?
In \( N \) tosses, you should get \(\frac{N}{2} \) heads right?
So, lets observe the difference \( N_H - \frac{N}{2} =\frac{D}{2} \).
The RMS deviation is given by \( (N_H- \frac{N}{2})_{\text{RMS}}=\frac{\sqrt{N}}{2} \).
Thus, an actual \( N_H \) deviates from \( \frac{N}{2} \) by about \( \frac{\sqrt{N}}{2} \), or the fraction to deviate by \( \frac{1}{N} \frac{\sqrt{N}}{2} \).
So, the larger the \(N\) , the closer we expect the fraction \( \frac{N_H}{N} \) to \( \frac{1}{2} \).
Sounds familiar right? we circled back to statistical regularity again!
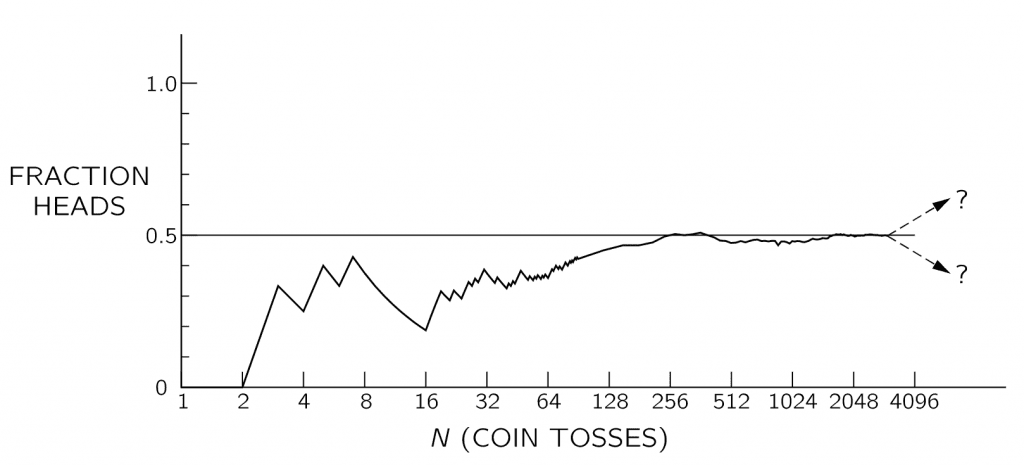
Unfortunately, for any given run or combination of runs there is no guarantee that the observed deviation will be even near the expected deviation. There is always the finite chance that a large fluctuation—a long string of heads or tails—will give an arbitrarily large deviation. All we can say is that if the deviation is near the expected \( \frac{1}{2 \sqrt{N}} \) , we have no reason to suspect the honesty of the coin. If it is much larger, we may be suspicious, but cannot prove, that the coin is loaded (or that the tosser is clever!).
If you still suspect the fairness of the coin, you should probably learn the Physics of Coin Tossing which Uttaran Chatterjee would address in the next blog.
This is mainly for our reader friends who like to visualize through coding.
Let's consider a simple game of chance using a spinner. But this game is somewhat kind to the gambler.In our game,the payoff in each of several repeated plays is determined by spinning the spinner. We pay an entry fee for each play of the game and then receive the payoff indicated by the spinner. Let the payoff on the spinner be distributed uniformly around the circle; i.e. if the angle after the spin is \( \theta \), he receives \( \frac{\theta}{2 \pi} \) rupees. Thus, our payoff on one play is \(U\) rupees, where \(U\) is a random number taking values in \([0,1]\). Clearly, this is gambling for the poor :P.
Let us simulate the game to see what cumulative payoffs the gambler might receive, not counting the entry fees obviously, if he plays the game repeatedly.
Construct partial sums \( S_k = U_1+U_2+...+U_k, 1 \le k \le n \).
The successive partial sums form a random walk, with \(U_n\) being the \(n^{th} \) step and \(S_n\) being the position after \(n\) steps.
walk <- function(j)
{
uniforms <- runif(10^j)
firstsums <- cumsum(uniforms)
sums <- c(0, firstsums)
index <- order(sums)-1
plot(index,sums,main="Random walk for for the partial sums",xlab="Number of trials",ylab="winnings",col=j)
}
par(mfrow=c(2,2))
walk(1)
walk(2)
walk(3)
walk(4)
We now present the 4 plots for 4 values of \(N\) , \(10,100,1000,10000 \).
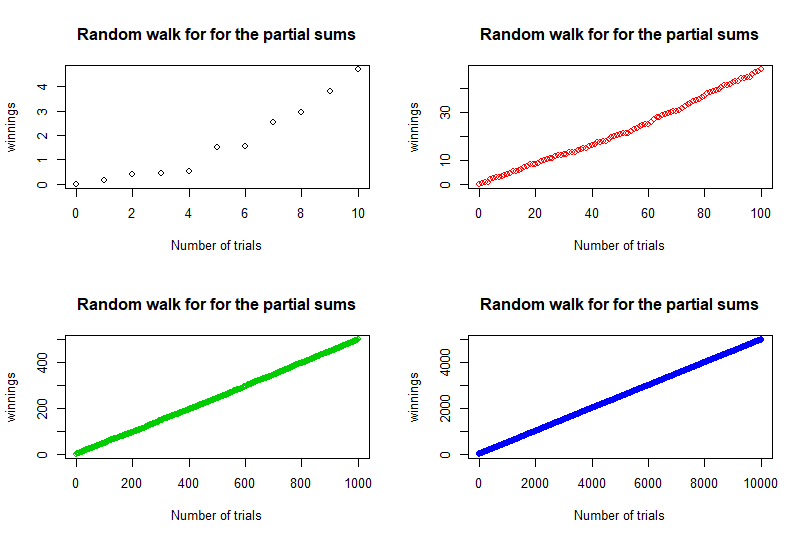
For small \(n\), that is for \(n=10\), we see irregularly spaced points increasing to the right, but as \(n\) increases, the spacing between the points becomes blurred and regularity emerges: the plots approach a straight line with slope equal to \( \frac{1}{2} \), the mean of a single step \(U_k\). If we look from a macroscopic point of view, ignoring the units on the axes, we see that the plots become independent of \(n\) as \(n\) increases. This is what regularity signifies.
Trust me, I just can't get enough of the Prime Number Theorem. Here is a short problem to think about for future researchers in this field.
Suppose a random walker starts at the point \( S_0 = 2 \), and walks according to the following rules:
1. If the walker is on the \( n^{th} \) prime number \( p_n \), he moves to either
\( p_n + 1 \) or \( p_{n+1} \) with equal probability.
2. If the walker is on a composite number \(x \), he moves to one of the prime factors of \(x \), each with probability \( \frac{1}{\omega(x) }\), where \(\omega(n) \) denotes the number of distinct prime factors of \(n\).
The random walk is given by the sequence of moves \(S_n\).
What can you say about the quantity \( \mathbb{P}(\sup_{n \ge 0} S_n = \infty) \) ?
Give it a try.
For our gambling game described above,if the expected payoff is \( \frac{1}{2} \) rupees each play of the game,the gamme is fair if the fee to play is \( \frac{1}{2} \) rupees.
Make a minor modification of this simulation by repeating the experiment after subtracting the mean \( \frac{1}{2} \) from each step of the random walk.
Now, plot the centered random walk (i.e. centered partial sums \(S_k - \frac{k}{2} \) for the same values of \(n\) as before.
Do you observe the same plots?
1.Experiencing Statistical Regularity - Ward Whitt
2.The Problem of The Random Walk- K.Pearson
3.An Introduction To Probability Theory and its applications - W.Feller
Stay tuned and keep following this series for getting more interesting perspectives on standard probability results and terms. I bet you too will see probability theory in a different light!
Keep learning, keep thinking!
Cheers..

In 2026, the following Cheenta students have been successful for Indian Statistical Institute's M.Stat Entrance. They ranked within the first 50 in the entire country in these entrances. I.S.I. M.Stat Entrance

In 2026, the following Cheenta students have been successful for Indian Statistical Institute's B.Stat Entrance and Chennai Mathematical Institute's B.Sc. Math Entrance. They ranked within the first 200 in the entire country in these entrances. Most of these students attended the problem solving workshops regularly, which happen 5 days every week. CMI B.Sc. Math Entrance […]

In 2025, 8 students from Cheenta Academy cracked the prestigious Regional Math Olympiad. In this post, we will share some of their success stories and learning strategies. The Regional Mathematics Olympiad (RMO) and the Indian National Mathematics Olympiad (INMO) are two most important mathematics contests in India.These two contests are for the students who are […]

Cheenta Academy proudly celebrates the success of 27 current and former students who qualified for the Indian Olympiad Qualifier in Mathematics (IOQM) 2025, advancing to the next stage — RMO. This accomplishment highlights their perseverance and Cheenta’s ongoing mission to nurture mathematical excellence and research-oriented learning.