12. $P(\pi)$ is even for all $\pi$. (Observe that there is one more odd than number of evens, so there will be one odd-odd match)
13. is equal to 12. (The $i,j$th element is $a_{ii}b{ij}c{jj}$. Use gp series then.)
14. 160 (Use the fact any permutation can be written as compositions of transpositions. Observe that the given condition is equivalent to that 2 transpositions are not possible)
15. $m_t < \infty$ for all $t \geq 0$ (All monotone functions are bounded on [a,b])
16.$H(x) = \frac{1-F(-x)+ F(x)}{2}$ (If $F(x)$ is right continuous, $F(-x)$ is left continuous.).
17. $\frac{1}{25}$ (Use the distribution function of $\frac{X}{Y}$)
18. 3 (Find the distribution of order statistic, and find the expectation)
19. (II) but not (I) (If $F(x)$ is right continuous, $F(-x)$ is left continuous.).
20. $20\lambda^4$ (Use gamma integral to find the $E(X_{1}^4)$.)
21. The two new observations are 15 and 5. (Use the condition to find two linear equations to find the observations).
22. It is less than 2. (Use the beta coefficients in terms of sample covariance and sample variance, and compare)
23. 4:3 (Use Bayes' Theorem)
24. The two-sample t-test statistic and the ANOVA statistics yield the same power for any non-zero value of $\mu_1 - \mu_2$ and for any $n,m$. (Both the test statistic are one to one function of one another)
25. t³-1 - 2(t-1)
26. $\frac{2 \sum_{i=1}^{n} X_i}{n(n+1)}$ (Use the invariance property of MLE)
27. $Y_1^2 + Y_2^2 + Y_1Y_2$ (Write the bivariate normal distribution in terms of $Y_1, Y_2$ and use Neyman Factorization Theorem.)
28. can be negative (Simson's Paradox)
29. $2z$ (There are three random variables, $N$ = stopping time to get $Y=1$, $Y$ and $X$. Use the conditioning properly. Take your time)
30. $\frac{40}{3}$ (Use the property that Poisson | Poisson in the given problem follows Binomial)
ISI MStat 2021 PSB Solutions
Coming soon.
ISI MStat PSB 2021 Problem 1
Solution
ISI MStat PSB 2021 Problem 2
Solution
ISI MStat PSB 2021 Problem 3
Solution
ISI MStat PSB 2021 Problem 4
Solution
ISI MStat PSB 2021 Problem 5
Solution
ISI MStat PSB 2021 Problem 6
Solution
ISI MStat PSB 2021 Problem 7
Solution
ISI MStat PSB 2021 Problem 8
Solution
ISI MStat PSB 2021 Problem 9
Solution
Please suggest changes in the comment section.
Cheenta Statistics Department ISI MStat and IIT JAM Training Program
Can Two or more Events be Exhaustive and Independent?
Can Two or more Events be Exhaustive and Independent?
Two Event Problem Formulation
Let $S$ be the sample space.
Let $A,B \subset S$ be two strict events with probability $p,q$ respectively.
The conditions are
$P(A \cap B) = P(A)P(B) = pq$ [Independent]
$P(A \cup B) = P(S) = 1$ [Exhaustive]
Do there exist such $A,B$? If yes, how do they look like?
ISI MStat Entrance 2020 Problems and Solutions PSA & PSB
This post contains ISI MStat Entrance PSA and PSB 2020 Problems and Solutions that can be very helpful and resourceful for your ISI MStat Preparation.
ISI MStat Entrance 2020 Problems and Solutions - Subjective Paper
ISI MStat 2020 Problem 1
Let f(x)=x2−2x+2. Let L1 and L2 be the tangents to its graph at x=0 and x=2 respectively. Find the area of the region enclosed by the graph of f and the two lines L1 and L2.
Find the number of 3×3 matrices A such that the entries of A belong to the set Z of all integers, and such that the trace of AtA is 6 . (At denotes the transpose of the matrix A).
Consider $n$ independent and identically distributed positive random variables $X_{1}, X_{2}, \ldots, X_{n}$. Suppose $S$ is a fixed subect of ${1,2, \ldots, n}$ consisting of $k$ distinct ekements where $1 \leq k<n$. (a) Compute $$ \mathrm{E}\left[\frac{\sum_{i \in s} X_{i}}{\sum_{i=1}^{\infty} X_{i}}\right] $$ (b) Assume that $X_{i}$ is have mean $\mu$ and variance $\sigma^{2}, 0<\sigma^{2}<\infty$. If $j \notin S$, show that the correlation between ( $\left.\sum_{i \in s} X_{i}\right) X_{j}$ and $\sum_{i \in}X_{i} $ lies between $-\frac{1}{\sqrt{k+1}}$ and $\frac{1}{\sqrt{k+1}}$.
Let X1,X2,…,Xn be independent and identically distributed random variables. Let Sn=X1+⋯+Xn. For each of the following statements, determine whether they are true or false. Give reasons in each case.
(a) If Sn∼Exp with mean n, then each Xi∼Exp with mean 1 .
Let U1,U2,…,Un be independent and identically distributed random variables each having a uniform distribution on (0,1) . Let X=min{U1,U2,…,Un}, Y=max{U1,U2,…,Un}
Suppose individuals are classified into three categories C1,C2 and C3 Let p2,(1−p)2 and 2p(1−p) be the respective population proportions, where p∈(0,1). A random sample of N individuals is selected from the population and the category of each selected individual recorded.
For i=1,2,3, let Xi denote the number of individuals in the sample belonging to category Ci. Define U=X1+X32
(a) Is U sufficient for p? Justify your answer.
(b) Show that the mean squared error of UN is p(1−p)2N
Consider the following model: $$ y_{i}=\beta x_{i}+\varepsilon_{i} x_{i}, \quad i=1,2, \ldots, n $$ where $y_{i}, i=1,2, \ldots, n$ are observed; $x_{i}, i=1,2, \ldots, n$ are known positive constants and $\beta$ is an unknown parameter. The errors $\varepsilon_{1}, \varepsilon_{2}, \ldots, \varepsilon_{n}$ are independent and identically distributed random variables having the probability density function $$ f(u)=\frac{1}{2 \lambda} \exp \left(-\frac{|u|}{\lambda}\right),-\infty<u<\infty $$ and $\lambda$ is an unknown parameter. (a) Find the least squares estimator of $\beta$. (b) Find the maximum likelihood estimator of $\beta$.
Assume that $X_{1}, \ldots, X_{n}$ is a random sample from $N(\mu, 1)$, with $\mu \in \mathbb{R}$. We want to test $H_{0}: \underline{\mu}=0$ against $H_{1}: \mu=1$. For a fixed integer $m \in{1, \ldots, n}$, the following statistics are defined:
\begin{aligned} T_{1} &=\left(X_{1}+\ldots+X_{m}\right) / m \\ T_{2} &=\left(X_{2}+\ldots+X_{m+1}\right) / m \\ \vdots &=\vdots \\ T_{n-m+1} &=\left(X_{n-m+1}+\ldots+X_{n}\right) / m . \end{aligned}
Fix $\alpha \in(0,1)$. Consider the test
reject $H_{0}$ if max {${T_{i}: 1 \leq i \leq n-m+1}>c_{m, \alpha}$}
Find a choice of $c_{m, \alpha}$ $\mathbb{R}$ in terms of the standard normal distribution function $\Phi$ that ensures that the size of the test is at most $\alpha$.
A finite population has N units, with xi being the value associated with the i th unit, i=1,2,…,N. Let x¯N be the population mean. A statistician carries out the following experiment.
Step 1: Draw an SRSWOR of size n(1 and denote the sample mean by X¯n
Step 2: Draw an SRSWR of size m from S1. The x -values of the sampled units are denoted by {Y1,…,Ym}
An estimator of the population mean is defined as,
Tˆm=1m∑i=1mYi
(a) Show that Tˆm is an unbiased estimator of the population mean.
(b) Which of the following has lower variance: Tˆm or X¯n?
Cheenta Statistics Department ISI MStat and IIT JAM Training Program
How to roll a Dice by tossing a Coin ? Cheenta Statistics Department
How can you roll a dice by tossing a coin? Can you use your probability knowledge? Use your conditioning skills.
Suppose, you have gone to a picnic with your friends. You have planned to play the physical version of the Snake and Ladder game. You found out that you have lost your dice.
The shit just became real!
Now, you have an unbiased coin in your wallet / purse. You know Probability.
Aapna Time Aayega
starts playing in the background. :p
Can you simulate the dice from the coin?
Ofcourse, you know chances better than others. :3
Take a coin.
Toss it 3 times. Record the outcomes.
HHH = Number 1
HHT = Number 2
HTH = Number 3
HTT = Number 4
THH = Number 5
THT = Number 6
TTH = Reject it, don't ccount the toss and toss again
TTT = Reject it, don't ccount the toss and toss again
Voila done!
What is the probability of HHH in this experiment?
Let X be the outcome in the restricted experiment as shown.
How is this experiment is different from the actual experiment?
This experiment is conditioning on the event A = {HHH, HHT, HTH, HTT, THH, THT}.
\(P( X = HHH) = P (X = HHH | X \in A ) = \frac{P (X = HHH)}{P (X \in A)} = \frac{1}{6}\)
One of the most controversial approaches to statistics, this post mainly deals with the fundamental objections to Bayesian methods and Bayesian school of thinking. Turning to the Bayesian crank, Fisher put forward a vehement objection towards Bayesian Inference, describing it as "fallacious rubbish".
However, ironically enough, it’s interesting to note that Fisher’s greatest statistical failure, fiducialism, was essentially an attempt to “enjoy the Bayesian omelette without breaking any Bayesian eggs" !
Ronald Fisher
Inductive Logic
An inductive logic is a logic of evidential support. In a deductive logic, the premises of a valid deductive argument logically entail the conclusion, where logical entailment means that every logically possible state of affairs that makes the premises true must make the conclusion truth as well. Thus, the premises of a valid deductive argument provide totalsupport for the conclusion. An inductive logic extends this idea to weaker arguments. In a good inductive argument, the truth of the premises provides some degree of support for the truth of the conclusion, where this degree-of-support might be measured via some numerical scale.
If a logic of good inductivearguments is to be of any real value, the measure of support it articulates should be up to the task. Presumably, the logic should at least satisfy the following condition:
Criterion of Adequacy (CoA): The logic should make it likely (as a matter of logic) that as evidence accumulates, the total body of true evidence claims will eventually come to indicate, via the logic’s measureofsupport, that false hypotheses are probably false and that true hypotheses are probably true.
One practical example of an easy inductive inference is the following:
" Every bird in a random sample of 3200 birds is black. This strongly supports the following conclusion: All birds are black. "
This kind of argument is often called an induction by enumeration. It is closely related to the technique of statistical estimation.
Critique of Inductive Logic
Non-trivial calculi of inductive inference are shown to be incomplete. That is, it is impossible for a calculus of inductive inference to capture all inductive truths in some domain, no matter how large, without resorting to inductive content drawn from outside that domain. Hence inductive inference cannot be characterized merely as inference that conforms with some specified calculus. A probabilistic logic of induction is unable to separate cleanly neutral support from disfavoring evidence (or ignorance from disbelief). Thus, the use of probabilistic representations may introduce spurious results stemming from its expressive inadequacy. That such spurious results arise in the Bayesian "doomsday argument" is shown by a re-analysis that employs fragments of inductive logic able to represent evidential neutrality. Further, the improper introduction of inductive probabilities is illustrated with the "self-sampling assumption."
Objections to Bayesian Statistics
While Bayesian analysis has enjoyed notable success with many particular problems of inductive inference, it is not the one true and universal logic of induction. Some of the reasons arise at the global level through the existence of competing systems of inductive logic. Others emerge through an examination of the individual assumptions that, when combined, form the Bayesian system: that there is a real valued magnitude that expresses evidential support, that it is additive and that its treatment of logical conjunction is such that Bayes' theorem ensues.
The fundamental objections to Bayesian methods are twofold: on one hand, Bayesian methods are presented as an automatic inference engine, and this raises suspicion in anyone with applied experience. The second objection to Bayes' comes from the opposite direction and addresses the subjective strand of Bayesian inference.
Andrew Gelman , a staunch Bayesian pens down an interesting criticism of the Bayesian ideology in the voice of a hypothetical anti-Bayesian statistician.
Here is the list of objections from a hypothetical or paradigmatic non-Bayesian ; and I quote:
"Bayesian inference is a coherent mathematical theory but I don’t trust it in scientific applications. Subjective prior distributions don’t transfer well from person to person, and there’s no good objective principle for choosing a non-informative prior (even if that concept were mathematically defined, which it’s not). Where do prior distributions come from, anyway? I don’t trust them and I see no reason to recommend that other people do, just so that I can have the warm feeling of philosophical coherence. To put it another way, why should I believe your subjective prior? If I really believed it, then I could just feed you some data and ask you for your subjective posterior. That would save me a lot of effort!"
Andrew Gelman
In 1986 , a statistician as prominent as Brad Efron restates these concerns mathematically:
"I like unbiased estimates and I like confidence intervals that really have their advertised confidence coverage. I know that these aren’t always going to be possible, but I think the right way forward is to get as close to these goals as possible and to develop robust methods that work with minimal assumptions. The Bayesian approach—to give up even trying to approximate unbiasedness and to instead rely on stronger and stronger assumptions—that seems like the wrong way to go.When the priors I see in practice are typically just convenient conjugate forms. What a coincidence that, of all the infinite variety of priors that could be chosen, it always seems to be the normal, gamma, beta, etc., that turn out to be the right choices?"
Well that really sums up every frequentist's rant about Bayes' 😀 !
And the torrent of complaints never ceases....
Some frequentists believe that in the old days, Bayesian methods at least had the virtue of being mathematically clean. Nowadays, they all seem to be computed using Markov chain Monte Carlo, which means that, not only can you not realistically evaluate the statistical properties of the method, you can’t even be sure it’s converged, just adding one more item to the list of unverifiable (and unverified) assumptions in Bayesian belief.
As the applied statistician Andrew Ehrenberg wrote :
" Bayesianism assumes:
(a) Either a weak or uniform prior, in which case why bother?,
(b) Or a strong prior, in which case why collect new data?,
(c) Or more realistically, something in between,in which case Bayesianism always seems to duck the issue."
Many are skeptical about the new found empirical approach of Bayesians which always seems to rely on the assumption of "exchangeability", which is almost impossible to obtain in practical scenarios.
Finally Peace!!!
No doubt, some of these are strong arguments worthy enough to be taken seriously.
There is an extensive literature, which sometimes seems to overwhelm that of Bayesian inference itself, on the advantages and disadvantages of Bayesian approaches. Bayesians’ contributions to this discussion have included defense (explaining how our methods reduce to classical methods as special cases, so that we can be as inoffensive as anybody if needed).
Obviously, Bayesian methods have filled many loopholes in classical statistical theory.
And always remember that you are subjected to mass-criticism only when you have done something truly remarkable walking against the tide of popular opinion.
Hence : "All Hail the iconoclasts of Statistical Theory:the Bayesians"
N.B. The above quote is mine XD
Wait for our next dose of Bayesian glorification!
Till then ,
Stay safe and cheers!
References
1."Critique of Bayesianism"- John D Norton
2."Bayesian Informal Logic and Fallacy" - Kevin Korb
Laplace in the World of Chances| Cheenta Probability Series
In this post, we will be discussing mainly, naive Bayes Theorem, and how Laplace, developed the same idea as Bayes, independently and his law of succession go.
I cannot conceal the fact here that in the specific application of these rules, I foresee many things happening which can cause one to badly mistaken if he does not proceed cautiously.
James Bernoulli
While watching a cricket match we often, try to predict what may happen in the next ball, and several time, we guess it correctly, I don't know much about others, but my predictions very often turns out to be true, even to the extent that, if I say, " may be Next ball will be an out-side edge caught behind by the keeper" and such thing really happens withing next 2 or 3 balls if not the immediate next ball. In college, I had a friend who could also give such precise predictions while watching a cricket match, even though he was not a student of probability. So, you see while at home or among friends, people think that we are getting lucky about our predictions.
Well, truly speaking, there's nothing wrong in that assumptions, we are indeed guessing and getting lucky. But what matters is our chance of getting lucky with our predictions is relatively higher than others !! While talking about chances, remember while making our judgements, we have no mathematical chances in our hand on which we are making predictions. What we just know is that, the proposition, we are predicting has reasonably higher probability than any other outcomes, we can think off. But how reasonable ?? Really No idea !! Actually see to take a decision regarding what may happen in the next ball, we don't need to know the mathematical probabilities, rather the need of developing probability is quite the other way around. i.e. for a judgement or proposition, you think its gonna happen or its true, we need to develop probabilistic calculation to judge how significant is my prediction.
Say, you are a manager of a cricket team(not an ordinary), and you need to pick a team for a future tournament, and you need to observe the performance in this current season, as you want to give a significant weightage on the current form of the players. So, here working with your instinctive judgements can even cost you your job. So, here you need to be sure about the relative-significance of your judgements, and take a final decision. We will come to these sort of problems, later while discussing about how decision making can be aided by Bayesian thinking. And that's where the real need of this theory lies. But as it happens, to apply first we need to our idea about the nature of these thinking quite clear. So, for now we will deal with some hypothetical but interesting problems.
Am I really Guessing ?
Well, it depends what definition of guessing you are setting. Ofcourse I was guessing, but the question is if my guesses are often correct, what is the possible explanation ?? The answer is quite simple, I'm not making judgements emotionally !! Often people realise that this may be their favorite batsman may miss a ton, but still stay emotional in predicting that !! What, parameters I always look into is the parameters where a sane probability believer will put his/her eyes on, i.e. How often, the batsman scores runs in consecutive matches, which bowler bowling and his\her ability ton swing the ball away from the batsman, in order to have an outside kiss from the bat, how often the batsman facing the ball, leaves or play balls outside off, etc etc etc. Any serious cricket lover will keep these things in account while making judgements. So, you see we are not actually guessing randomly. We are using information from every single ball. Hence, I'm always updating the chance of the propositions which I think may happen, with the information, I'm extracting after each ball is played. In precise our decision making is itself a Bayesian Robot, if and only if we are ready to give our biases !!
Naive Bayes
We have already discussed about how the seed of inverse thinking to establish possible causal explanation was planted by Thomas Bayes. (if you haven't read our previous post, here it is Bayes and The Billiard Table | Cheenta Probability Series ). The astonishing thing is that, even though Bayes' idea of evaluating inverse probability using available information was intuitive and mathematical enough, it still remained unknown or criticized if known in most of the Europe. There were mainly two reasons for that, first, may advanced thinking was not the cup of tea which the 18th century mathematicians and probability people, were ready to drink, they eventually needed the evolution of Computer to drink that cup completely, and the second reason was that, even though Bayes' idea was intuitive and radical, it needed serious mathematical support, or it would have collapsed.
So, Bayes idea was quite simple and elegant. Suppose you have a suspicion, say \(S\), say the batsman will not score a ton. Then, you have a set of information say \(I\), say that s\he scored a ton in the last match. So, the chance (or expectation) of your suspicion \(S\) to be come true, when you have observed \(I\) is the ratio of the chance (or expectation) that you had observed this kind of information \(I\), when actually your suspicion was correct and the chance of observing what you have observed i.e. chance of observing \(I\). So, mathematically,
\(P(S|I)=\frac{P(I|S)P(S)}{P(I)}\)
If we break down the \(P(I)\), using Total Probability (or expectation) law, (remember !!), then we will get the form of Bayes theorem, we are accustomed to see in our textbooks,
Hence, here our Prior probability is \(P(S)\) .i,e. chance of your suspicion to be true, gets updated to the posterior probability \(P(S|I)\), i.e. chance of your suspicion to be true when you have observed some information supporting or doubting your suspicion. The point is you state about the truth of your prediction is changing towards the reality !
Now in the above, expression, the place where controversies arises, is what is the nature of \(P(S)\) ? that is how often, your (our), suspicion about a particular thing turns out to be true ? Here comes our hypothetical problem of Extrasensory Perception which we will ultimately converge in to the Law of Succession, developed by none other than the great Laplace.
Laplace Places his Thoughts
Now, suppose we are interested to know what is the chance, that my guess about the next next ball will be correct, when it is already known that some of the guesses I made earlier turned out to be correct.
Let, I, have made \(n\) guesses earlier as, \(G_1,G_2,....,G_n\) among which \(k\) guesses turned out to be correct, now if I make another guess say, \(G_{n+1}\), what is the chance that my current guess will turn out to be true ?
Now, we will present the solution to this problem, but we will first develop the the story and intuition developed by one of the pioneer of this field. The solution turned out to be a law in future.
Thoughts are often like noises, that pops-up here and there, when in England, Bayes's hidden work got published and didn't got due attention, then in other part of Europe, the similar thoughts pops-up in the mind of young but brilliant Pierre-Simon Laplace. Now obviously I don't need to say more about who he is.
Perrie-Simon Laplace
That was the era when Astronomy was most quantified and respected branch of science. The Science was looking forward to test Newton's Theories by explaining how precisely gravitation effects the movements of tides, interacting planets and comets, our moon, and the shape of the Earth and other planets. Years of Empirical data was collected. The Scientists and astronomers everyday went to sleep with the fear that, a single exception in their expected data could bring the entire edifice tumbling down. The question which all mattered is whether the Universe is stable !!
Astronomers, knew the planets are moving. There came a time some of them feared that slowly accelerating Jupiter will smash into the Sun someday !! The problem of predicting the motions of many interacting bodies over long periods of time is complex even today, and Newton concluded that God's miraculous intervention kept the heavens in equilibrium.
Laplace who was an Astronomer turned mathematician, took it as a challenge to explain the stability of the Universe and decided dedicating his thoughts in that. He said that while doing this Mathematics will be his telescope in hand. For a time being, he started considering ways to modify Newtons's theory of gravitation by making gravity vary with a body's velocity as well as with its mass and distance. He also wondered fleetingly whether comets might be disturbing the orbits of Jupiter and Saturn. But he changed his mind almost immediately. He realised the problem was not Newtons Theory, but the data collected by the astronomers.
Newtons's system of Gravitation, could have been verified, only if the measurements would come precise and as expected. But observational astronomy was awash with information, some of it uncertain and inadequate. That's where Laplace felt the need to introduce probability in his scientific research. This is also a very important moment for probability theory, it came out from its gambling table and got preference on the papers of a scientist. But still Laplace was far enough from the Bayesian ideas, which he was to develop in future.
In next five years Laplace wrote 13 papers in solving problems in astronomy and mathematics of celestial mechanics but still was rejected from getting membership, in French Royal Academy of Sciences. Then a time came when he actually started considered , of emigrating to Prussia to work in their academies. During this frustrated period, when he used to spent his afternoons digging in mathematical literature in libraries. And remember he was still worried about the problem with the errors in the measured astronomical data, and was beginning to think that it would require a fundamentally new way of thinking, may be probability theory to deal with the uncertainties prevading many events and their causes. That is when he began to see the light. And in that light he found the same book, which even stimulated the grey cells of Thomas Bayes, just a decade ago, he got "The Doctrine of Chances" by Abraham de Moivre. May be Laplace studied a new version of the book, unlike Bayes.
Laplace's growing interest in probability theory created a diplomatic problem, stalwarts like d'Alembert believed probability was too subjective for developing scientific arguments. But Laplace was young and daring to bring revolution in the thinking. He was quite sure that only probability can help him in getting precise solution while dealing with the complex problems of movements in celestial bodies. And in the process he immortalized Probability Theory while finding its application in such a higher form of scientific investigations. He began thinking, how he can find an causal explanation, behind the divergence in the error filled observations. He independently developed a thought behind developing " Probability of Causes" derived from the already happened events.
In is first paper on this topic, in 1773, atheist Laplace compared ignorant mankind, not with God but with an imaginary intelligence capable of knowing it all. Because humans can never know everything with certainty, probability is the mathematical expression of our ignorance : "We owe to the frailty of the human mind one of the most delicate and ingenious of mathematical theories, namely the science of chance or probabilities."
He often said he did not believe in God, but neither her Biographer could decipher whether he was an atheist or a diest. But his probability of causes was a mathematical expression of the universe, and for the rest of his days he updated his theories about God and probability of causes as new evidence became available.
Laplace's Principle of Succession
Laplace, at first dealt with the same problem as Bayes, about judging the bias of a coin, by flipping it a number of times. But, he modified a version which was quite identical to the philosophical problem, proposed by Hume, which asks the probability that the sun going to rise tomorrow when you know that sun is being rising everyday for the past \(5000\) years. Observe that it also very much coincides with the problem of guessing I presented at the beginning of this section.
He developed his principle, which mathematically equates as the formula we came across in the Naive Bayes, infact that form of Bayes rule is more due to Laplace than due to Bayes himself !! So, using his principle, and accepting the restrictive assumption that all his possible causes or hypotheses were equally likely, he started using the Uniform prior. Laplace calculates the probability of success in the next trial ( sun rising tomorrow ), given there are \(n\) successes earlier in all \(n\) trials.
He, defined, a variable ( which we call Random Variable), \(X_i \) which takes value of \(1\), if success comes at \(i\) th trial or \(0\) if failure. Now, with what probability, a success will come that is unknown to us, and that what the unknown bias is, hence he took that chance say, \(p\) to be distributed uniformly within the interval, \((0,1)\). Let the probability density of \(p\), be \(f\). Now, let \(S_n\) be the number of success in \(n\) trials. Then, \(S_n= X_1+X_2+....+X_n\). Here, \(S_n=n\). So, we need, \(P(X_{n+1}=1 |X_1=1,X_2=1,....,X_n=1)\) which is precisely, \(P(X_{n+1}|S_n=n)\).
Laplace principle was, The probability of a cause ( success in the next trial) given an event ( past \(n\) trials all resulted in success) is proportional to the probability of the event, given the cause. Which is mathematically,
Now, see that the event of success in next trial can occur with probability \(p\) that we don't yet know, and wish to know. So, with \(X_{n+1}=1\) we are actually claiming the chance of success is \(p\), which is uniformly distributed within \((0,1)\). So, Now the question is what a should be the constant of proportionality ?? Laplace is witty enough to answer that the constant of proportionality is nothing but the normalizing constant of the posterior probability, \(P(X_{n+1}=1 |S_n=n)\) !! Since we know, conditional probabilities are also probabilities and they also follow the conglomerability and adds up to 1. Hence, in this case, the required constant is \(\frac{1}{P(S_n=n)}\) .
Now, in our statement of proportionality becomes,
\(P(X_{n+1}=1|S_n=n)=\frac{P(S_n=n|X_{n+1}=1)P(X_{n+1}=1)}{P(S_n=n)}\). Isn't it look like the Bayes rule we all know !!
Now there are two, ways the probability can be computed, I will present the elegant and more complicated way, the other you can search yourself!!
As, I was discussing that, the event \(X{n+1}=1\) is bijective to the even that the success chance is some \(p\). So,
\(P(S_n=n|X_{n+1}=1)P(X_{n+1}=1)=P(S_n=n| success \ probability \ is p \ is \ uniform \ in \ 0<p<1 )P(X_{n+1}=1|success \ probability \ is p \ is \ uniform \ in \ 0<p<1) \\= \int^1_0 p^n p \,dp= \frac{1}{n+2}\), integrated since we consider all values within the interval \((0,1)\) has same density i.e. \(f(p)=1\) when \(0<p<1\). Now our required posterior is,
\(P(X_{n+1}=1|S_n) \propto \frac{1}{n+2}\),
Now, one can verify that, our normalizing constant, \(P(S_n=n)\) is\( \frac{1}{n+1}\). Use, Law of total probability over \(0<p<1\), using the prior density of \(p\). Hence, finally, Laplace got,
\(P(X_{n+1}=1|S_n=n)=\frac{n+1}{n+2}\). Hence the chance of the sun rising tomorrow when it has risen, past \(n\) days is \(n+1\) out of \(n+2\). Now, the solution to the guessing problem is also a matter of assessing the same arguments, which I leave in the hands of the reader, to find out. Another thing to note here, that Laplace, was the first called this conditional probability as likelihood, which became a quite important part of literature in Bayesian inference.
This principle, then went on to be known as the "Laplace Law of Succession". The rationale behind the nomenclature is, that with the information about the outcome of every trial, one can update the information about the chances of the success, in a successive order. Just like Thomas Bayes updated his information about the position of his read ball relative to the position of each black ball rolled on the billiard table.
Notice that for large numbers of trials an application of Laplace's rule is very close to simply taking the relative frequency of heads as ones's probability for heads the next time. In this setting, with a lot of data, naive frequentism does not go far wrong. But who, on initially getting two heads, would give probability one on heads the next time ?
Laplace Generalizes
Now, the controversy or may be in some cases, fallacy of this more rightfully called, Bayes-Laplace Rule, was at the uniform approximation of the priors. Suppose a flat prior is not appropriate. That is in most cases the coin may be biased, but it is unlikely to be very biased. Perhaps one might want a prior like a symmetric bell-shaped distribution,
The Symmetric Prior ; Beta with n=m=10
or it may be more likely to be biased in one direction having a skewed bell-shaped prior.
The Skewed Prior ; Beta with n=5, m=10
Then the questions arises are, Can the simplicity and tractability of the Bayes-Laplace analysis be retained ? It can. We choose an appropriate prior density proportional to the likelihood.
As, I discussed in the solution above, Laplace, wittily used the normalizer of the posterior probability of distribution, as the constant of proportionality, which further made the prior density to integrate to \(1\).
The distribution we basically considered in the above solution could be generalized by Beta distribution, whose shapes are governed by the parameters of it that are often names as \(n\) and \(m\). The density of beta looks like,
\(\frac{p^{n-1}(1-p)^{m-1}}{normalizer} \), here, the Bayes-Laplace flat prior has both \(n\) and \(m\) equals to 1. While in the symmetric bell-shaped prior, which is peaked at \(\frac{1}{2}\), has both \(n\) and \(m\) to be equal to \(10\), whereas in the second case of the skewed prior, the \(n\) is taken to \(5\) and \(m\) kept same as \(10\).
Now, since the principle of Laplace states the prior density is proportional to the likelihood, pilling up frequency data keeps the updated density in the beta family. Suppose starting with parameters \(n\) and \(m\), in a squence of \(t\) trials, we incurred \(s\) successes. Hence, our new beta density will have parameters \(n+s\) and \(m+(t-s)\). The resulting rule of succession gives us the probability of success for the next trial, on the evidence of \(s\) successes in \(t\) trials, as \(\frac{s+n}{t+n+m}\),
Clearly as claimed at the end of the last section, this ratio almost becomes the relative frequency \(\frac{s}{t}\), for large number of trials, which again swamps the prior. How fast this swamps the prior that depends on the magnitude of \(n\) and \(m\).
This is here where we can actually look into not only the predictive power of this rule, but also how it updates its densities about the unknown.
Priors Modified for Coin Tossing
Suppose, we have \(62\) heads in \(100\) tosses. The updated densities from our uniform, symmetric, and skewed priors doesn't show much difference. Bernoulli's inference from frequency to chance doesn't look too bad here, but now we know what assumptions we had to make to get that result.
The Posteriors after 100 tosses, for corresponding priors.
There are limited number of shapes that can be made with beta priors. Now if one is aware of the technicalities of coin tossing, then one might want a different shape to quantify their state of prior ignorance. Persi Diaconis, a dedicated Bayesian and an experienced person regarding coin tossing, points out that coins spun on edge tend to be biased one way or another but more often towards tails. So, if an unknown coin is to be spun, Persi would prefer to put his beliefs on a bimodal prior density with somewhat higher peak on the tails' side, which can't be represented by beta distribution. However, we can represent such distributions, by mixtures of two beta densities, one peaked towards heads and one peaked towards tails, where the second peak is of higher altitude. Updating on frequency evidence is still relatively simple, treating the two betas as metahypotheses and their weights as prior probabilities.
More generally, one has a very high rich palette of shapes available for quantifying prior states of beliefs using finite mixtures of betas. Arguably one can get anything one might find rational to represent their prior mixture of knowledge and ignorance. As before, with lot of evidence such niceties will not matter much. But if we are going to risk a lot on the next few trials, it would be prudent for us to devote some thought to putting whatever we know into our prior.
Laplace continues...
Having his principle structured , he first applied his new, "probability of causes", to solve two gambling problems when he realized that his principle need more modification. In each case he understood intuitively what should happen but got bogged down trying to prove it mathematically. First problem, we worked with an urn filled with black and white tickets in an unknown proportion ( his cause). He first drew some number of tickets from the urn and based on that experience, asked for the probability that in the next draw his ticket will be white. To, prove the answer , he fought a frustrating battle and had to write \(45 \) equations, covering every corner of four quarto-sized pages. Today those \(45\) equations became redundant, or better to say reduced and compressed within of lines of simulation codes.
His second problem involved a piquet, a game requiring both luck and skill. Two people start playing but stop midway through the game and have to figure out how to divide the kitty by estimating their relative skill levels ( the cause). This problems, surely reminds us about the problems on which Pascal and Fermat worked, but there they both assumed that the players have equal skills. Laplace's version is more realistic.
With these two gambling problems, Laplace dealt with two very important perspective of uncertainties, first that is unknown parameter, first problem quite remarkably portrays the basic motive of Statistical Inference. And in the second problem, he dealt with even more finer perspective of uncertainty, that is Chance and Causes, which in future make this Bayes-Laplace model to be an important and comprehensive tool in drawing conclusion in the new Science of Cause and Effect.
Laplace, was then to move towards solving his actual problems in astronomy. How should they deal with different observations of the same phenomenon ? He was all set to address three of that era's biggest problems, that involved Gravitational attraction on the motions of our moon, the motions of the planets Jupiter and Saturn, and shape of the Earth. We shall keep the application of Bayesian Probabilities in these astronomical problems for some other day.
Laplace eventually credits Bayes
Eventhough, after the surfacing and developments of the Bayesian perspective, Statistical fraternity, got divided into the two groups of Frquentists and Bayesians, ironically, both Bayes and Laplace were neutral themselves. Bayes, even in his published essay, referred his dependencies on the frequencies while get an idea about his prior assumption, and never ignited the debate neither foresee such kind of debates in future.
Similarly Laplace, in his book on Probabilities, acknowledges the relative resemblances in his principle of Probability of Causes and frequency methods, which I tried putting light on, in the previous sections. He besides from being the resurrecting Bayes' rule, also invented the Central Limit Theorem, which is more kind of an Frequencist's tool than a Bayesians'.
When Laplace started grappling with his probability of causes, and attacking problems in celestial mechanics in 1781, Richard Price arrives Paris and informed them about the discovery of Bayes'. Laplace immediately latched onto Bayes' ingenious invention, the starting guess, and incorporated it into his own, earlier version of the probability of causes. Hence, he was now confident that he was on the right track in assuming the prior causes equally likely, and assured himself about the validity of his principle. Everytime he gets a new information he could use the answer from his last solution as the starting point for another calculation, That is he goes on successively. And by assuming all the prior causes equally likely, he could now formulate his principle into a law or a theorem. Though soon he was to realise about the shortcomings of his assumption of equally likely, and hence the need for generalizing, which we already talked about a bit under the section Laplace Generalizes.
Laplace later credited Bayes with being first when he wrote, "The theory whose principles I explained some years after,.... he accomplished in an acute and very ingenious, though slightly awkward, manner. "
Although Bayes originated the probability of causes, Laplace discovered the same on his own. When, Bayes' Essay eas published by his friend Price, Laplace was only 15. The approach and the principle both Bayes and Laplace developed are independent mathematically speaking. We will be discussing in more details the mathematical perspectives of both Laplace and Bayes in our coming articles.
Till then, stay safe, and keep finding the solutions for the Gambling Problems Laplace worked on, they no more need 45 equations to be solved nowadays !!
References
1.Probability Theory- the logic of science - E.T.Jaynes
2. A Philosophical Essay on Probabilities - Peirre-Simon Laplace
3. The theory that would not Die- Sharon Bertsch Mcgrayne
Bayes and The Billiard Table | Cheenta Probability Series
This is the first of the many posts, that I will be writing on the evolution of Bayesian Thinking and Inverse Inferences, in Probability Theory, which actually changed Statistics from a tool of Data interpretation to Causal Science.
When the facts change, I change my opinion. What do you do, sir ?
-John Maynard Keynes
In the climax of our last discussion, I kept my discussion about the Jelly-bean example incomplete to begin here afresh. (If you haven't read that, you can read it before we start, here it is Judgements in a Fitful Realm | Cheenta Probability Series ). There we were actually talking about the instances, how evidences can exihibit chanciness in this uncertain world. Today we will discuss how we can update our beliefs or judgements ( Judgemental Probabilities), based on these uncertain evidences, provided we have observed a pattern in the occurrence of this so-called circumstantial evidences.
Or in more formal literature, it is referred as Inverse-Inference, as we will first observe some outcomes and then we will go deeper investigating the plausible explanations in terms of chances, so as to have some presumed idea about future outcomes . There arises two immediate questions,
How does it helps in predicting or foresee future ?
Why a causal explanation should depend on probabilities ?
Before discussing these questions, let us discuss about the structure and some ideas behind this way of Probability Analysis. I hope with some example, the reader will able to answer the above questions themselves, and eventually appreciate this particular school of thought which inspite of lot of controversies inspired independent fields of Statistics, which made statistics one of the most important knowledge of this century. Statistics doesn't remain just a mere tool of data interpreting but, is now capable of giving causal explanations to anything and everything, from questions like whether "Smoking Causes Cancer", or " What is the chance of having a Nuclear accident?".
A century earlier, asking this sort of questions to a statistician, was outrageous, as most of the statisticians ( very likely to be egoistic), would not admit their inability in answering these sorts, would say more likely " its not answerable, due to lack of evidences", or in other words implying, "in order to find the chance of a nuclear accident, you first need to organize a planned nuclear accident !!"
Bayes makes his Glorious Entry
In 1763, in an article, "Essays towards solving a Problem in Doctrine of Chances", as authored by Thomas Bayes, he put his ideas as,
"Given the number of times in which an unknown event happened or failed.
Required the chance that probability of its happening in a single trial lies somewhere between any two degrees of Probability that can be named. "
Its Strange, that what Bayes stated is so coinciding with the idea of conglomerability stated by De Fenetti nearly after 200years. This is where, I feel the evolution of probability theory is so perplexing, since often quite advanced ideas emerged earlier, and then there basic explanations were put in to words afterwards. And then, there are people who put these pieces of jigsaw puzzles in places, we will come back to this works later some other day.
As Bayes' gravestone suggests, he died in 1761 at the age of 59. After 2 years of his death, his friend Richard Price, published his Essay. Price communicated the essay, together with an introduction and an appendix by himself to the Royal Society, got it published in its Philosophical Transactions in 1763. Price, while referring to Bayes' idea writes,
Rev Thomas Bayes like his rule, there lies controversies regarding this portrait also !! But unfortunately is the only available portrait, where this person is believed to be Bayes with all certainties.
".....he says that his design at first thinks of the subject of it was, to find out a method by which we might judge concerning the probability that an event has to happen, in given circumstances, upon the supposition that we know nothing concerning it but that, under the same circumstances, it has happened a certain number of times and failed a certain other number of times. "
Basically, Bayes was talking about a machinery which would find the predictive probability that something will happen, next time, from the past information. Bayes predecessors, even including Bernoulli and de Moivre, had reasoned from chances to frequency. Bayes gave a mathematical foundation for- inference from frequencies to chances.
Even though, with advancement of his theory, Bayes' rule found many useful application from Breaking Enigma, to answering whether, Smoking causes Cancer or many other sorts, Bayes himself was not motivated to put his ideas on paper for solving a practical problem, on the contrary what motivated Bayes, was a philosophical debate which demanded mathematical argument. To, me what Bayes' idea propagates is the sole uniformity and subjectivity of nature. In one way it makes us convince that we are by virtue dependent on chances, but on the other hand it suggest with every new information, we always have a scope of improving our ideas about the uncertainty, which seemed more uncertain, before that extra bit of information. It simply tells, that it all depends on some God damn Information.
Bayes sees the Light
An incendiary mix of religion and mathematics exploded over England in 1748, when the Scottish philosopher David Hume published an essay attacking some of fundamental narratives of organized religions. Hume believed that we can't be absolutely certain about anything that is based only on traditional beliefs, testimony, habitual relationships, or cause and effect.
As it happens, God was regarded as the First Cause of everything, Hume's skepticism about cause-and-effect relationships was especially unsettling. Hume claimed that there is always association between certain objects or event, and how they occur. Like the earlier discussion, we are likely to umbrella on a rainy day, so there is a strong association with the weather and your carrying of umbrella, but that doesn't any how implies your umbrella is the cause why it is cloudy out there, rather its the other way around. This was a pretty straight forward illustration, but as Hume illustrates more philosophically, that,
"....Being determined by the custom transfer the past to the future, in all our inferences; where the past has been entirely regular and uniform, we expect the event with the greatest assurance, and leave no room for any contrary supposition. But where different effects have been found to follow from causes, which are to appearance exactly similar, all these various effects must occur to the mind in transferring the past to the future, and enter into our consideration, when we determine the probability of the event. Though we give preference to that which has been found most usual, and believe that this effect will exist, we must not overlook the other effects, but must to each of them a particular wei9ght and authority, in proportion as we have found it to be more less frequent. "
What actually, Hume tried to claim is that, you are taking umbrella that also even doesn't imply, its rainy or cloudy even, it may happen that you will use the umbrella to protect yourself from the heat, it may be less likely ( for a given person), but still not at all unworthy of neglecting it completely. And most important, the "design of the world" does not prove the existence of a creator, an ultimate cause. Because we can seldom be certain that a particular cause will have a particular effect, we must be content with finding only probable causes and probable effects.
Even though, Hume's essay was not mathematically sound it had profound scientific food for Bayes to think over it and develop a mathematics to quantify such probabilities. Many mathematicians and scientists used to believe that the inexplicability of the laws of the Nature, proves the existence of God, their First Cause. As de Moivre put it in his "Doctrine of Chances" , calculations about natural events would eventually reveal the underlying order of the universe and its exquisite "Wisdom and Design".
The arguments, motivated Bayes, and he became keen to find ways to treat these thoughts mathematically. Sitting in that century, directly develop a probabilistic mathematics was quite difficult, as the idea of Probability was itself not very clear to the then Thinkers and Mathematicians. It was that era, when people would only understand Gambling, if you utter the word Chance. By that time, while spending his days in French Prison ( because he was a Protestant), De Moivre already had solved a gambling problem, when he worked out from cause-to-effect( like finding the chance of getting four aces in one poker hand). But still no-one ever thought of working a problem other way around, i.e. predict the causes, for an observed effect. Bayes, got in interested in questions as, what if a poker player deals himself four aces in each of the three consecutive hands ? What is the underlying chance (or cause) that his deck is loaded ?
As, Bayes himself kept his idea hidden until his fried Price, rediscovered it, it is very difficult to guess what exactly piqued Bayes' interest in the problem of inverse probability. Though he was aware of De Moivre's works, and getting interested in probability as it applied to gambling. Alternatively, it may also happen that, he was worried about the cause of Gravity, that Newton suggested, but Newton neither gave any Causal validation of Gravity , nor he talked about the truthfulness of his theory. Hence this also can be the possible reason, why he got interested in developing mathematical arguments, to predict the cause from observed effects. Finally Bayes' interest may have been stimulated by Hume's philosophical essay.
Crystallizing the essence of inverse probability problem in his mind, Bayes decided that his ai is to achieve the approximate chance of a future event, about which he knew nothing about except the pattern regarding its past occurrence. It is guessed that sometime sandwiched between 1746 and 1749, when he developed an ingenious solution. To reach the solution Bayes devised a thought experiment, which can be metaphorically referred as a 1700s version of a computer simulation. We will get to the problem, after discussing a bit about how Bayes, modified the frequency interpreting of probability.
Bayes Modifies
At the very beginning of the essay Bayes takes the liberty to modify the general frequency interpretation, and ended up defining conditional probability, and as it happens his definition of probability were actually remarkable anticipations of the judgemental coherence views, which were developed by likes of De Fenetti and Ramsay, years after. After defining what we call mutually set of mutually exclusive and exhaustive set of events, Bayes goes forward explaining probability as,
"The Probability of any event is the ratio between the value at which an expectation depending on the happening of the event ought to be computed, and the value of the thing expected upon its happening. "
Like a true probabilist, Bayes defined probability from a gambling point of view, talking about payoff as an outcome of each event. But we also can treat the result itself as the payoff or expected value as a result of certain events.
As we already discussed and I tried to make the point several time, that probability of any event can be interpreted as the weighted average of the judgemental probabilities ( conditional probabilities), which are obtained while observing some available evidences, and the weights of the so-defined mean are the probability of observing those evidences.
\(P(A)=P(A|E_1)P(E_1)+P(A|E_2)P(E_2)+........+P(A|E_n)P(E_n)\) ; here A is any event, which is depending on some set of Evidences, say \(E={E_1, E_2,.....,E_n}\).
Though very important restriction imposed by Bayes here is that, the set of possible evidences must be mutually exclusive and form an exhaustive set. i.e. \(E_1,E_2,....,E_n\) are mutually exclusive and exhaustive set.
This visualization of probability is important, once you enter the Bayesian regime. Moreover, even though frequency probability is our basic and primary understanding of probability, I find this interpretation of judgemental probabilities or sometimes also called Likelihoods( we will see later), more general model of probability, though a bit of abstraction associated, but that the true nature of an art, right ! And probability is an Art !
so, getting back to Bayes' definition of probability, mathematically speaking, If your total Judgement about an experiment (or gamble) is \(N\) (that is you put \(N\) unit on contract in case of gamble), and the there is an event \(e\), then the payoff from your investment of \(N\), you may expect from the occurrence of the event \(e\) is \(N.P(e)\), or
\(P(e)=\frac{ Expected \ value \ of \ out \ of \ N, \ if \ e }{N}\)
where, \(P(e)\) as the chance of the event \(e\). He completes his definition by claiming that "by Chance I mean Probability".
On basis of this definition, Bayes argues for the basic properties of probability, like additivity of disjoint probabilities in terms of additivity of expectations. But I choose not to elaborate here, as we already discussed about this in our last post and also in the post about Conglomerability. ( read this article, for more elaborate discussion Nonconglomerability and the Law of Total Probability || Cheenta Probability Series ).
Opening page of Bayes' Essay
Bayes goes on to establish the definition of conditional probability. He gives a separate treatment for the case where the conditioning event precedes the conditioned one and the case where the conditioning is subsequent to the conditioned one. The latter case is a bit perplexing as it is saying like some thing already happened, now we need to travel back the time and find what might have happened (behind the scene), such that it can explain our observation. But thats what Bayes claimed to find right !! So, here Bayes give a very interesting argument in his fourth proposition, where he invites us to consider an infinite number of trials determining the occurrence of the conditioning and conditioned events,
"If there be two subsequent events to be determined every day, and each day the probability of the 2nd is \(\frac{b}{N}\) and the probability of both \(\frac{P}{N}\), and I am to receive \(N\) if both events happen on the 1rst day on which the 2nd does ; I say, according to these considerations, the probability of my obtaining \(N\) is \(\frac{P}{b}\)....."
So, what Bayes says is on the first day either the condition happens- or if not he is facing the same wager as before :
"Likewise, if this coincident shouldnot happen I have an expectation of being reinstated in my former circumstances."
This is to say, the Probability that a event occurring, when you already observed that another event has occurred already, is just the ratio of the Expectation of the coincidence ( that both the desired event and the event which occured happened) and the Expectation of the the event that has occurred. Some time this ratio is often referred as the likelihood of the desired event, while using it in the Bayesian Probability structure.
taking the gambling realm as Bayes, the probability of win on the supposition that \(E_2\) ( the second ) did not happen on the first day is just the original probability of a win. Let us assume unit stakes, so that expectation equals Probability, to simplify the exposition.
Then letting \(E_1\) be the first event and \(E_2\) the second , he argues as follows:
\(P(win)=P(win \ on \ day \ 1)+P(win \ later)\)
\(= P(E_1 \ and \ E_2)+P( not \ E_2)P(win)\)
\(=P(E_1 \ and \ E_2)+ (1-P(E_2))P(win)\)
\(P(win)=\frac{P(E_1 \ and \ E_2)}{P(E_2)}\).
This is what Bayes considered as the probability of \(E_1\) on the supposition \(E_2\) is taken as a corollary ( that is \(E_2\) has occurred or true ), but the exposition of the corollary contains an interesting twist, it goes like,
"Suppose after the expectation given me in foregoing proposition, and before it is all known whether the first event has happened or not, I should find that the second event has happened; from hence I can only infer that the event is determined on which my expectation depended, and have no reason to esteem the value of my expectation either greater or less than before. "
Here with expectation, he always means the odds of that particular event, and now I explained several times how probability can actually be interpreted as expectation, so I hope readers face no difficulty ( unfamiliarity may still exist) while going along with this kind of literature.
Now, Bayes gives a money-pump argument :
"For if I have reason to think it less, it would be reasonable to give something to be reinstated in my former circumstances, and this over and over again as I should be informed that the second event had happened, which is evidently absurd. "
He concludes explaining the opposite scenario as,
"And the like absurdity plainly follows if you say I ought to set a greater value on my expectation than before, for yhen it would be reasonable for me to refuse something if offered on the condition that I relinquish it, and be reinstated in my former circumstances...."
These arguments by Bayes gives two basic implications that, eventhough he didn't developed the sound mathematics of the nature of the probabilities he proposed, he had the idea of coherence and by extension conglomerability, which were yet to be put into mathematical literature.
Bayes in front of the Billiard Table, Finally !!
With conditional probability in hand, Bayes proceeds to the problem with which he begins the Essay. Suppose a coin, about whose bias we know nothing at all, has been flipped \(n\) times and has been heads \(m\) times. If \(x\) is the chance that coin comes up heads on a single toss, Bayes requires
\( P( x \ in \ [a,b] | m \ heads \ in \ n \ tosses) \) .
\(=\frac{P(x \ in \ [a,b] \ and \ m \ heads \ in \ n \ tosses)}{P(m \ heads \ in \ n \ tosses)}\).
To evaluate this, Bayes must assume something about the prior probability density over the chances. Prior probability density is the basically the prior (or initial) information about the desired unknown (here it is \(x\)), which he first assumes, and then he went on finding the required probability, which is called the posterior probability, based on the priors he assumed and the observations he made. So, basically he keeps updating his knowledge about the desired unknown starting with a mere information about the desired unknown (\(x\)). But the controversy arises where, he assumes the prior probability, or he makes an assumption about the prior information, that is the overall pattern on the nature of \(x\). We will come to these later, first express Bayes' final touches while completing the solution.
Now Bayes assumes a uniform prior density as the correct quantification of knowing nothing concerning it. Anticipating that this might prove controversial, as I mentioned above, and of course it has, he later offers a different justification in a scholium. On this basis, he applies Newton's calculus to get,
How are these to be solved? Bayes evaluates integral in the denominator by a geometrical trick. This is Bayes' "billiard table" argument.
Bayes' "Billiard Table" illustration as done by him in his Essay.
Suppose we throw a red ball at random on a table and mark its distance from the leftmost side. Now then we toss \(n\) black balls one by one on the table, as shown in the figure.Lets call a ball that falls to the right of the red ball a head and one that falls to the left a tail. This corresponds to choosing a bias at random and flipping a coin of that bias \(n\) times. Now nothing hangs on the first ball being the red one. We could just throw \(n+1\) balls on the table and choose the one to be the red ball, the one to set bias, at random. But if we choose the leftmost ball to the red one, all is black balls count as heads and if we choose the right one to be the red ball, no black balls count as heads, and so forth. Thus the probability of \(m\) heads in \(n\) tosses is same for \(m=0,1,....,n\), hence the required probability must be \(\frac{1}{n+1}\). This is the value of the integral in the denominator. The integral in the numerator is harder and no such close form solution exists. Bayes however gives a way of approximating it too.
In scholium , Bayes uses his evaluation of the denominator to argue for his quantification of ignorance. He argues that, he knows nothing about the event except that there are \(n\) trials, he have no reason to think that it would succeed in some number of trials rather than another. Hence, he suggests that there is nothing wrong in taking
\(P(m \ heads \ in \ n \ tosses)=\frac{1}{n+1}\), as our quantification of ignorance about outcomes. The uniform prior, in fact follows from this - although Bayes did not have the proof !!
Priors to Posteriors- Journey Continues !
Once Bayes suggested a way of solving the inverse problem, of finding a bias of a coin given you observed a numbers of heads out of a number of tosses,
Or even extending the "billiard table" argument, suppose you are facing towards the wall and I threw the red ball and it stopped some where on the table, now you need to actually pin-point the position of the red ball, so I kept tossing each black ball (\(n\) times ) and noting whether the black ball is landing towards the left of the red ball or the right, now using this information about the black ball with respect to the randomly placed red ball, you can actually have the idea about the portion of the table where the red ball had stopped, right ! Bayes already answered that !!
Now say if you want to be more precise about the position of the red ball, so you requested me to throw another set of \(n\) balls, and repeat what I was doing. But now you have extra bit of information, that is you atleast know the possible portion of the red balls, from the posteriors, that Bayes calculated for you, so now you don't need to make the uniform assumption, whereas now you can you your newly acquired information, as your new prior and again update your posterior to an improved posterior probability about where on the damn table, your red ball rests.
So, this is where the genius of Bayes, takes probability to another level, using two most beautiful aspects of mathematics, that is inverse thinking and recursion.
We will get back into the next discussion, where we will be discussing about more example, the aftermath of the Bayesian introduction in the world of uncertainty, the man who did everything to give Bayesian Probability its firm footing, and obviously, "How to calculate the probability that the sun will rise tomorrow, given it has risen everyday for 5000years !!" .
Till then, stay safe, and keep finding the red ball on the billiard table, but don't turn around !!
2. The theory that would not Die- Sharon Bertsch Mcgrayne
3. Ten Great Ideas About Chance- Skyrms, Diaconis
Nonconglomerability and the Law of Total Probability || Cheenta Probability Series
This explores the unsung sector of probability : "Nonconglomerability" and its effects on conditional probability. This also emphasizes the idea of how important is the idea countable additivity or extending finite addivity to infinite sets.
**10 min read**
“I believe that we do not know anything for certain, but everything probably.”~ Christiaan Huygens
One week into conditional probability, it's time to get our hands dirty with the Law of Total Probability and paradoxes which have emerged out of it.Let's be formal enough to state the law first.
The Law of Total Probability
Adorably called LOTP , it is one of the cardinal results in Conditional Probability.
Suppose the events \(A_1,A_2,...,A_k \) are a partition (mutually exclusive and exhaustive) of the event space and let \(H\) be any arbitrary event of the event space then it states that \(P(H)=P(H|A_1)P(A_1)+P(H|A_2)P(A_2)+...+P(H|A_k)P(A_k) \)
k=6
The day to day event I always relate to while recalling this law is that Suppose you have a thin glass block placed on a table and accidentally some water has been spilled on it. A part of this water has been trapped in between the surface of the table and the glass. If you look at this from above, you will see a puddle of water almost circular,trapped within the rectangular block. This puddle is actually our arbitrary event \(H\) and our block the event space. How can you get the partitions? Any wild guesses? Well, drop a hard stone on the glass and it cracks, or even if you have strong arms and like fantasizing about hurting your knuckles, you can do it too :P. The cracks partition the sample space into various segments and there is water trapped in each of them. There you go!
As we have stressed already, from a false proposition, or from a fallacious argument that leads to a false proposition - all propositions true and false, may be deduced.But this is just the danger;if fallacious reasoning always led to absurd conclusions,it would be found out at once and corrected.But once an easy , shortcut mode of reasoning has led to a few correct results, almost everybody accepts it; those who try to warn against it are generally not listened to.
When a fallacy reaches this stage, it takes on a life of its own and develops very effective defenses for self preservation in the face of all criticisms.Here is one such instance.
Nonconglomerability
If \( (C_1,C_2,...,C_n )\) denote a finite set of mutually exclusive, exhaustive propositions on prior information I , then for any proposition \(A\), we have:
As you all seen in the previous blog post, the prior probability \(P(A|I)\) is written as a weighted average of the conditional probabilities \( P(A|C_i I) \).
Now, it is an elementary result that the weighted mean of a set of real numbers cannot lie outside the range spanned by those numbers, i.e. if \( L \le P(A|C_i I) \le U \) ; then necessarily \( L \le P(A|I) \le U \).
De Finetti (1972) called this property as "conglomerability" of the partition \( \{C_i\}\).
Obviously, non-conglomerability cannot arise from a correct application of the rules of probability theory on finite sets.It cannot, therefore occur in an infinite set which is approached as a well defined limit of a sequence of finite sets.
Yet nonconglomerability has become a minor industry, with a large and growing literature.There are writers who believe that it is a real phenomenon, and that they are proving theorems about the circumstances in which it occurs, which are important for the foundations of probability theory. Nonconglomerability has become, quite literally, institutionalized in our literature and taught as truth.
Let us examine some case where "nonconglomerability" has been claimed to be true.
Rectangular Array
This particular example by the famous trio Kadane,Schevish and Seidenfeld (1986).
We start from a 2 dimensional \( (M \times N) \) set of probabilities: \( p(i,j) , 1 \le i \le M ; 1\le j \le N \).The sample space is a rectangular array of \( MN \) points in the first quadrant. It will suffice to take some prior information \( I \) for which these probabilities are uniform : \(p(i,j) = (\frac{1}{MN} ) \). Let us define the event \(A : i<j \).
Therefore, \(P(A|I)\) can be found by direct counting and in fact it is given by :
\( P(A|I) = \begin{cases} \frac{(2N-M-1)}{2N}, & M \le N \\ \frac{(N-1)}{2M}, & N \le M \\ \end{cases} \)
Now let us resolve this conditionally, using the partition \(\{C_1,C_2,...,C_M\}\).We have \(P(C_i |I)=\frac{1}{M} \).
So, we get \( P(A|C_i I) = \begin{cases} \frac{(N-i)}{N}, & 1 \le i \le M \le N \\ \frac{(N-i)}{N}, & 1 \le i \le N \le M \\ 0 & N \le i \le M \\ \end{cases} \)
These conditional probabilities reach the upper and lower bounds \( U= \frac{(N-1)}{N}, \forall M,N \) and
\(L=1-R \) ; if \(M \le N\) and \(0\) otherwise, where \( R=\frac{M}{N} \).
Now, if we check the conglomerability criteria using these \(L,U\) , then it seems to work fine with no ambiguity. So, where can one possibly create a non-conglomerability out of this?
Just take \( M \rightarrow \infty, N \rightarrow \infty \) and look at the probabilities \( P(A|C_i I) \). We try to evaluate these probabilities directly on the infinite set.
Then it is argued that, for any given \(i\), there are an infinite number of points where \( A \) is true and only a finite number where it is false.Thus, the conditional probability \(P(A|C_i I) =1 \) for all \(i\); yet \(P(A|I) <1 \).
Now, consider the set of propositions \( \{D_1,D_2,...,D_N \} \) , where \( D_j\) is the statement that we are on the \(j^{th}\) row of the array,counting from the bottom.Now, by the same argument , for any given \( j \) , there are an infinite number of points where \(A\) is false, and only a finite number where \(A\) is true.
Then, the conditional probability \(P(A|D_j I)=0 ; \forall j\) , yet \(P(A|I) >0 \).By this reasoning, we have produced two nonconglomerabilities, in opposite directions, from the same model!!
But wait wait wait... aren't we missing something? I don't think this is a fallacy at all. Let's think of this elementary problem in analysis:
It was Gauss who pointed out that any given infinite series \(S=\sum_{i} a_i \) converges to any real number \(x\) as per your choice.
Suppose you define the partial sums \(s_n =a_1 + a_2 + ... +a_n \). Define \(s_0=0\).
Write \(a_n = (s_n - x) - (s_{n-1} -x ), so our series becomes:
The terms \( (s_1-x), (s_2-x),....\) cancel out and BOOM !! your sum is \( S=-(s_0 -x)=x \).
Pause for a moment and taste the BLUNDER 😛
Hadn't a great man once said:
Apply the ordinary processes of arithmetic and analysis only to expressions with a finite number n of terms. Then after the calculation is done, observe how the resulting finite expressions behave as the parameter n increases indefinitely.
Yes, exactly! even stalwarts like Gauss, Weierstrauss,Abel and many accompanying them did not follow this advice meticulously and in many cases reached wrong conclusions. If you can understand the fallacy of this proof, you can pretty well admire the forgery in the rectangular array problem.
Once one has understood the fallacy in the analysis problem, then whenever someone claims to have proved some result by carrying out arithmetic or analytical operations directly on an infinite set, it is hard to shake off a feeling that he could have proved the opposite just as easily and by an equally sound argument, had he wished to. Thus there is no reason to be surprised by what we have just found.
Nonconglomerability on a rectangular array, far from being a phenomenon of probability theory, is only an artifact of failure to obey the rules of probability theory.
Bourbaki were the first to point out the fallacy
Borel-Kolmogorov Paradox
Another abuse of conglomerability , this has its name written down in the history books.
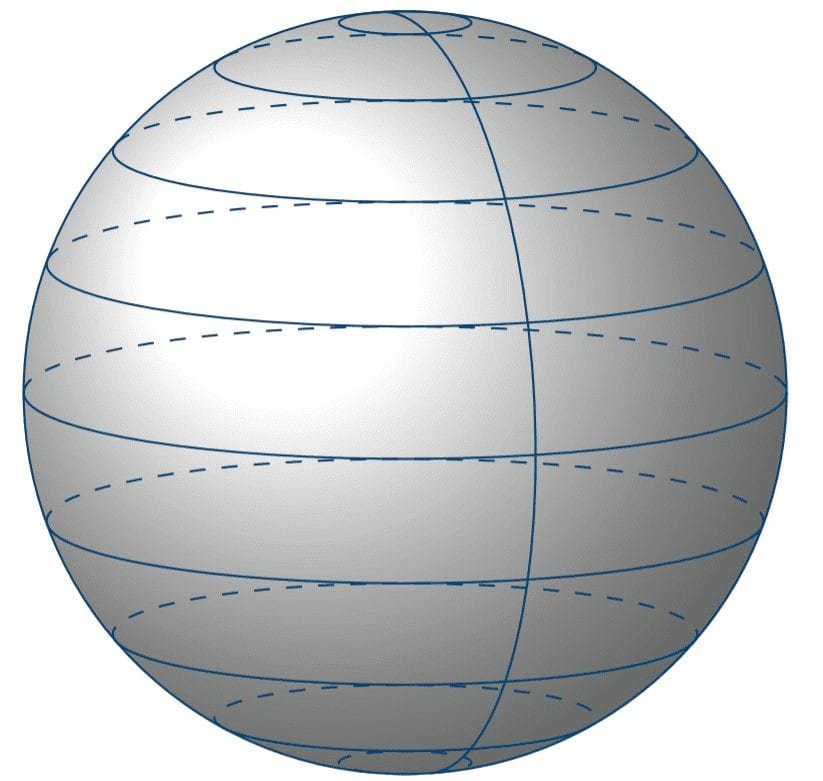
Suppose a random variable has a uniform distribution on a unit sphere. Now we choose a point randomly. We will do this in two ways:
1.Choose longititude \( \lambda \) uniformly from \([-\pi,\pi] \).
2. Choose latitude \( \phi \) from \( [-\frac{\pi}{2},\frac{\pi}{2}] \) with density \( \frac{1}{2} \cos \phi \)
The problem asks us to find the conditional distribution of \(X\) on a great circle.
Because of the symmetry of the sphere, one might expect that the distribution is uniform and independent of the choice of coordinates. However, two analyses give contradictory results. First, note that choosing a point uniformly on the sphere is equivalent to choosing the longitude \( \lambda \) uniformly from \( [-\pi, \pi] \) and choosing the latitude \( \phi \) from \([-\frac{\pi}{2}, \frac{\pi}{2}] \).
For a line with longitude with \( \lambda =0 \) , \(f(\phi| \lambda=0) = \frac{1}{2} \cos \phi \) .
Whereas, for a line with latitude \( \phi=0 \), \( f(\lambda| \phi=0) = \frac{1}{2 \pi} \).
One is uniform on the circle , while the other is not! Yet both refer to the same great circle :O
Now, I am not going to geek the resolution of this paradox as it requires greater knowledge in probability theory which we will surely cover in future posts. But interested readers can go through E.T. Jaynes' explanation of the same.
We will be back with a few more posts in conditional probability and will try our best to enamor you with the various angles and spheres which are less trodden in probability.
Till then stay safe.
Have a great weekend!
References:
1. Conglomerability and finite Partitions - Alan Zame
2. The Extent of Non Conglomerability of Finitely Additive Probabilities- Kadane, Schervish, Seidenfeld
3.Probability Theory- the logic of science - E.T. Jaynes
Judgements in a Fitful Realm | Cheenta Probability Series
This post discusses how judgments can be quantified to probabilities, and how the degree of beliefs can be structured with respect to the available evidence in decoding uncertainty leading towards Bayesian Thinking.
The object of reasoning is to find out, from the consideration of what we already know, something else, which we do not know. Consequently, reasoning is good if it be such as to give a true conclusion from premises, and not otherwise.
-C.S. Pierce
In our quest for the actual form of uncertainty, and developing laws of chances, one of the most important thing is being judgemental.
Always, in life you don't have the luxury to observe a particular event finitely many times, and structure it in a known equiprobable frequency set-up as we have always tried in case of measuring chances. For example you just can't go out on finitely many cloudy days without an umbrella, to observe how many of the days it actually rains and you get wet. Of course, you can conduct this experiment, but on conducting such experiment, you could end up catching cold or even pneumonia.
But then again, if one fine day you woke up and see that its cloudy out there, and you felt that it may rain today so you carried your umbrella, but fortunately it didn't rained and carrying your umbrella was not of much use, so next similar day you didn't care to carry the umbrella and it rained !! : p
So, here you just relied in your judgement, which made you believe in the first day it would rain, but since it didn't rained again your judgement made you believe that it wouldn't rain the next day also, and you were misled by your judgement. So, now if you conclude that you should not rely on circumstantial judgement ! But again you are wrong ! Why ?? Well, that's what we are going to discuss here.
Can Beliefs be measured ?
Relying on personal beliefs and preferences, may not be encouraged well enough in conventional science, as it should not be, but mathematicians like Bruno De Fenetti, Frank Plumpton Ramsey and some others, suggested that if beliefs or judgements are made measurable (like we measure chances), then we can definitely keep our faith on them. So, now the question is are beliefs measurable ?? Won't those measures will be subjective ??
Ramsey answers that too, in this essay "Truth and Probability" Ramsey writes,
"It is a common view that belief and other psychological variables are not measurable, and if this is true our inquiry will be vain ; and so will the whole theory of probability conceived as a logic of partial belief; for if the phrase 'a belief two-thirds of certainty ' is meaningless, a calculus whose sole object is to enjoin such beliefs will be meaningless also. Therefore unless we are prepared to give up the whole thing as a bad job we are bound to hold that beliefs can to some extent be measured."
He continues,
"But I think beliefs do differ in measurability in the following two ways. First, some beliefs can be measured more accurately than others; and, secondly, the measurement of beliefs is almost certainly an ambiguous process leading to a variable answer depending on how exactly the measurement is conducted. The degree of a belief is in this respect like the time interval between two events; before Einstein it was supposed that all the ordinary ways of measuring a time interval would lead to the same result if properly performed. Einstein showed that this was not the case; and time interval can no longer be regarded as an exact notion, but must be discarded in all precise investigations.
I shall try to argue that the degree of a belief is just like a time interval; it has no precise meaning unless we specify more exactly how it is to be measured. But for many purposes we can assume that the alternative ways of measuring it lead to the same result, although this is only approximately true. The resulting discrepancies are more glaring in connection with some beliefs than with others, and these therefore appear less measurable. Both these types of deficiency in measurability, due respectively to the difficulty in getting an exact enough measurement and to an important ambiguity in the definition of the measurement process, occur also in physics and so are not difficulties peculiar to our problem; what is peculiar is that it is difficult to form any idea of how the measurement is to be conducted, how a unit is to be obtained, and so on. "
Now as Ramsey suggests that the idea, of how the beliefs will be measured was crucial here, but the had the answer for that too. What the did is that the made their judgements heavily dependent on the evidences, which the assumed to be quite certain. Though later we will see that evidences are not always certain, but that doesn't makes their measure falsified. Just we need additional machinery to handle the discrepancy in the evidence.
What De Fenetti and Ramsey did, is they expressed judgements and partial beliefs as mathematical probabilities, and believe me its here this mathematics of probability gets immensely powerful and beautiful. Now it is here where you feel that you can express every thought of yours in terms of mathematics.
In our last posts, we have always been talking about equiprobable cases, now even in the equiprobable scenario , your judgements are disguised as symmetry, and hence you don't even realize that you are judgemental by virtue. one of the obvious instance which exposes our virtue of being judgemental is we don't even consider the possiblity of a coin landing on its edge , which ( i discussed elaborately earlier) is afterall not impossible ( may be improbable). So, here we are putting our judgements on the nature of the coin .i.e. " its too thin to land on its edge".
Wise man always carries an Umbrella
"Any fool carries an umbrella on a wet day, but the wise man carries it every day. "— Irish Proverb
Coming back to our example of the cloudy day, here you have no set of nice equiprobable set of cases, that can determine the chance of rain.
Well obviously you can say vaguely, " it rains or it doesn't, so its like a coin tossing " , or you may further suggest, " I have been observing, that its been raining more or less 4 days a week, so the chance of raining today is about 57% ." But the thing is, What about the overcast condition, is it not making you inclined towards the conclusion, "its going to rain" ? But again the question is how much we should be inclined towards the proposition "its going to rain" ?
De Fenetti would have said that since, you are certain about the fact that its cloudy, looking for the chance of raining is like ignoring the evidence that your are privileged of. That is here we must not look for the chance of raining as it is, rather here we must find the chance of raining when you already saw, that it is overcast out there. So, our judgement about rain is basically quantified as the probability of rain conditioned on the evidence that its cloudy.
So, if we say, \(R\) is the event (or proposition) "its going to rain" and \(C\) is another event(or proposition), "there is a cloud-cover". Then probability that its going to rain, i.e. \(P(R)\)is basically transformed to \(P(R|C)\), where we read this as "Probability its going to rain, given that there is a cloud cover". Hence the forecast you going to make is basically a coherent judgement of the situation which is basically expressed as conditional probabilities. So, here the concept of probability, reaches a spiritual level ( if I may say so ), where it is actually quantification of our belief based on evidences which are apparently certain. But still the question of transformation of belief to probability stays alive to be killed. :p
Believing in Probabilities
Beliefs as such are definitely a vague thing to put our trusts upon, but once there is a mathematical support behind a particular belief it remains no longer inferior as mathematics herself stands with all her might to defend it.
Now extending our example of cloudy day, suppose you have quite a few detailed observations. Say you observe that during monsoon more or less 4 days a it stays overcast ( from the morning ), and again as you further observed that 3 of the cloudy days end up being a rainy day, and you already observed that 4 days a week it rains (more or less).
So, when it is known that it is cloudy out there, the chance of downpour becomes 3 out of 4 ( or \(\frac{3}{4}\)), by your judgement. This is actually the chance generated from your coherent judgements are probability indeed.
Bruno De Fenetti often refereed as a "radical probabilist"
De Fenetti showed that coherence is equivalent to one's judgeents having the mathematical structure of probability. He argued the judgements in a mathematical structure behaves like a proportion. (like in the above example we quantified our judgement by "3 out of 4" which is a proportion indeed ).He explained that while defining the chance of raining when you have observed the overcast conditions already, such chances ( judgemental probabilities as called by De Fenetti) are basically proportions of classical probability of two propositions "its going to rain" and "its cloudy out there", i.e. \(P(R|C)\) is basically the ratio of \(P( R \ and \ C)\) (we read this as , probability that its going to rain when it is cloudy ou there )and \(P(C)\) (probability of its cloudy out there). So, \(P(R|C)=\frac{P(R \ and \ C)}{P(C)}\). Hence,
a proportion minimizes to 0.
it also maximizes to 1.
Proportions of a combination of mutually exclusive parts ,i.e. out of 4 cloudy days 3 of them ends up being rainy, and out of 3 clear sky-days (from morning) , 1 day it rains ( in the evening may be due to sudden accumulation of clouds) so the total proportion of rainy day a week is 4 out of 7.
Hence, De Fenetti, showed that coherent judgements can be mapped to mathematical probabilities. He clarified the validity of other way also.
Suppose \(D_i\) represents the total number of rainy day in \(i^{th}\) week when it was cloudy. So the total number of expected rainy days sums up as,
\(E(D_1+D_2+......)=E(D_1)+E(D_2)+......... \)
Now clearly, here as the individual expectations are non-negative, then there definitely non-negative number of rainy days on an average. Concluding that judgements that are mathematical probabilities are coherent.
Hence, De Fenetti concluded,
"Judgemental probabilities are coherent if and only if they have the mathematical structure of classical probabilities."
De Fenetti used Gambling problems to illustrate this concept, but I tried to with a more basic scenario of cloudy-rainy day, as illustrating gambling problems requires a different kind of literature which is too elaborate to explain in a breif discussion, though interested readers can go further and look for De Fenetti's illustrations.
Ramsey Completes the Circle
So, we already extended our visualisation of judgements as probabilities, but still the circle remains incomplete as yet we haven't came back to the classical set up, from judgemental probabilities. We have used classical probability structure to quantify judgements and re-structure judgements as probabilities and calculated the chances of raining and taking decisions on things like, whether you should carry an umbrella or not.
We are however helping ourselves to the classical equally probable cases and stipulating that the agent in the question takes them to be equally probable. (the agent is Cloudy-Raindy-Day example is you, who is taking the decision, whether to carry an umbrella). Ab thoroughgoing judgemental account would get all probabilities out of personal preferences. Now you might be tempted to say thats impossible. but that is what exactly Ramsey accomplished in his essay "Truth and Probability".
We have already got the rationale towards building our beliefs or judgements, what is still missing is Symmetry or in Ramsey's words idea of "ethically neutral" proposition. This is a proposition, \(p\) whose truth or falsity in and of itself, makes no difference to an agent's preferences. That is to say for any collection of outcomes \(B\) , the agent is indifferent between \(B\) with \(p\) true and \(B\) with \(p\) false.
Extending, the Cloudy-Rainy-day example, if i say that you have an exam and you have to go out, idi9fferent of the fact its is cloudy or not, here "its cloudy out there" is an "ethically neutral" proposition with subject to your choice of going out.
Now we can identify an ethically neutral proposition, \(h\) with probability \(\frac{1}{2}\) as follows. Consider two outcomes, \(A\) and \(B\) such that you prefer the 1rst one to the 2nd. then the ethically neutral proposition \(h\) has probability \(\frac{1}{2}\) for you if you are indifferent between [\(A\) if \(h\); B otherwise] and [\(B\) if \(h\); A otherwise]. This the key idea. We can you this over and over to re-construct our judgements, but that is something for some other day.
Frank P Ramsey who not only revolutionized probability theory but also combinatorics in his short lifetime.
Ramsey goes to the Race Course
Now what De Fenetti called judgemental probabilities, Ramsey called it degree of beliefs of outcomes and we call that conditional probability today. I will use Ramsey's literature, hoping that readers will do the necessary mappings (with conditional probability). the reason I chose Ramsey's notations is because, I want our readers to understand the real intuition and motive behind formalizing conditional probabilities, which actually validates the conclusion,
"Conditioning is the soul of Judgements".
So, we will end our discussion, with a problem that explores the nature of the idea of "ethically neutral", as readers may find the clarification over this idea will be most helpful while understanding Law of Total Probability and what actually defines Stochastic Independence.
The Horse race
Consider four propositions HH, HT, TH, TT, which are mutually exclusive and jointly exaustive ( as outcomes of tossing two coins). Farmer Smith doesn't really care which of these is true. More specifically, for whatever way the things he does care about could come out, he is indifferent to their coming out that way with HH or with HT, or with TH, or with TT. Then in Ramsey's terminology these four propositions are ethically neutral.
Suppose, in addition, that for any things he does care about, \(A\) prefered to \(B\) preferred to \(C\) preferred to \(D\), he is indifferent between the gamble
\(A\) if HH,
\(B\) if HT,
\(C\) if TH,
\(D\) if TT,
and any other gamble that can be gotten by rearranging \(A\), \(B\) , \(C\), \(D\) , for instance,
\(D\) if HH,
\(B\) if HT,
\(C\) if TH,
\(A\) if TT.
Then for him HH,HT, TH, TT all have the same probability , equal to \(\frac{1}{4}\). (Perhaps this is because these events represents what he takes to be two independent flips of a fair coin and he is making judgements like Pascal and Fermat, as discussed earlier.)
Now, suppose Farmer Smith went on to bet on a Horse race. There is to be a race in which the horses, Stewball and Molly, compete. Farmer smith owns Stewball, and the propositions Stewball wins and Molly wins are not ethically neutral for him. He can wager on the race, with the prospect of winning a pig if the horse he wagers on wins.
His most prefered outcome is get pig and Stewball wins, that is with all certainty he is going to get the pig when Stewball wins, so he assigns 1 to its belief for this outcome, and symmetrically he will not get anything if Stewball loses, so he assigns 0 as the degree of belief to that outcome. These are just arbitrary choices of how to scale his degree of beliefs :
1 | Get Pig and Stewball wins
:
:
:
0| No Pig and Stewball loses.
Farmer Smith is indifferent between : get pig and Molly wins and a hypothetical gamble that would ensure that he would get the Pig and Stewball would win if HH or HT or TH and that would get the pig and Stewball lose if TT, but that gamble will increase his degree of belief of having the pig by \(\frac{3}{4}\), so our new scale of beliefs is, ( basically what he does is chooses to toss two coin which replaces the condition of winning of Stewball )
1 | Get Pig and Stewball wins:
\(\frac{3}{4}\) | Get Pig and Molly wins,
:
:
0| No Pig and Stewball loses.
He is indifferent between no pig and Molly loses and the hypothetical gamble that would ensure that he would get the pig and Stewball would win if HH and that he will get no pig and Stewball would lose if HT, TH or TT. Now we have
1 | Get Pig and Stewball wins:
\(\frac{3}{4}\) | Get Pig and Molly wins,
:
\(\frac{1}{4}\) | No Pig and Molly wins,
0| No Pig and Stewball loses.
He is indifferent between the gamble get pig if Molly wins and no pig is she loses and the gamble get pig and Stewball wins if HH or HT, but no pig and Stewball loses if TH or TT. The first gamble is not conditioned on ethically neutral propositions, but it is equated to 1; that is the gamble get pig and Stewball wins if HH or HT, but no pig and Stewball loses if TH or TT has expected belief \(\frac{1}{2}. 1+ \frac{1}{2}. 0 = \frac{1}{2}\). So the first gamble, pig if Molly wins and no pig if she loses, must also satisfy
that is chance of getting the pig while conditioning on the proposition of Molly's win, is ethically neutral .
Here the conditional probabilities are actually the degree of beliefs that we scaled using the hypothetical gamble, here those believes are \(\frac{3}{4}\) and \(\frac{1}{4}\) respectively, Farmer's judgemental probabilities, in order to have Molly's win as an ethically neutral proposition, \(P(Molly's \ win)= \frac{1}{2}\).
Ramsey started with the coherent preference of ordering and showed how exact probabilities and degrees of beliefs such that the preferences are in accord with the expected belief i.e. the unconditional (classical) probability. This is a representation theorem for probability and degree of belief. Coherent preferences can be represented as coming from judgemental probability and personal beliefs by the rule of conditioning on (seemingly) certain evidences.You can call this kind of judgements as " Wishful Thinking" also.
Can Evidences be Uncertain ?
Before finishing, just trying to create some excuse to carry on the discussion some other day. Observe that through our structuring degrees of beliefs to judgemental probabilities, we considered that the evidences on which we are conditioning our preferences, are more or less certain, like cloudy sky(you can see that), or Molly's win ( though not certain as such but given Molly wins or loose it gains certainty). But there are instances where this evidences that are available to us are uncertain itself.
Richard C Jeffrey who revolutionized Decision Theory
In Richard Jeffrey's Probability Kinematics he discussed that there is no evidential proposition that we earn with certainty. Rather, the evidential experience causes shifts in the possibilities of the other propositions conditional on members of evidential partition unchanged. This leads to rich general conception of updating with connections to minimal change of probabilities.
Like in our example of Cloudy-Rainy-Day, the evidence that it is overcast (from morning) can change due to the infuence of some more uncertain evidential alterations like direction of wind, speed of wind which is fortunately or unfortunately taking the clouds with her. But whatever it is, it is quite certain that this alterations in the circumstantial evidences will impact your judgements, and you need to update your judgements to improve the possibilies of raining.
Jeffrey illustrates a nice example, suppose you get up at night and observe, by the dim light in through the window, a jellybean sitting on a table. Jellybeans that might possibly be there are red, pink, brown or black. The light is not good enough to shift your probabilities . This is a case of uncertain observation, there is no proposition available to sum up the content of your observation. We might try saying that as much as we observe is a proposition itself, but that is not a proposition based on which you can define a reasonable probability space.
So, we need to find some other supporting evidence that can serve as the propositions on formalizing the judgemental probabilities, suppose the flavors of the jellybeans perhaps !! Like a red one might be cherry or cinnamon. A brown one may be chocolate or coffee. There are all sorts. Now can you think of using these conditions wisely?! Think it over, until we meet again.
To bring coherence to bear, assume that we have coherent rule for updating certain evidence. By the argument given it must be a rule of conditioning on the evidence, but what is the chance of observing a particular evidence, in the world of uncertain happening? Its paradoxical isn't it !!
Wait for Bayes, he will come to rescue you from here !!
Probability From A Frequentist's Perspective || Cheenta Probability Series
This post discusses about the history of frequentism and how it was an unperturbed concept till the advent of Bayes. It sheds some light on the trending debate of frequentism vs bayesian thinking.
***10 min read***
"The probable is that which for the most part happens" - "Rhetoric",Aristotle
Frequentism
Hopefully this example will be able to explicate the true sense of the word:
Suppose, I have misplaced my phone somewhere in my home. I can use the phone locator on the base of the instrument to locate the phone and when I press the phone locator the phone starts beeping.
Now the question is which area of my home should I search?
Apparently, there are two clear approaches to this problem:
Approach 1:
I can hear the phone beeping. I also have a mental model which helps me identify the area from which the sound is coming. Therefore, upon hearing the beep, I infer the area of my home I must search to locate the phone.
Approach 2:
I can hear the phone beeping. Now, apart from a mental model which helps me identify the area from which the sound is coming from, I also know the locations where I have misplaced the phone in the past. So, I combine my inferences using the beeps and my prior information about the locations I have misplaced the phone in the past to identify an area I must search to locate the phone.
The first approach, which is probably the trite way out defines frequentism or reflects a person's frequentist ideas or beliefs.
The second approach surely, as you have guessed already is how a Bayesian thinks.
Now, I am not going into the debate on which approach is better Frequentist or Bayesian ? Being a fan of Bayesian thought processing myself, I hear that many contemporary statisticians feel that the Bayesians have lobbied into the limelight with their "crooked" mindset of unnecessarily complicating things. Rather I will like to elucidate Approach 1 , it's history and the present scenario of frequentist statistics.
A Brief History of Frequentism
The term 'frequentist' was first used by M.G. Kendall in 1949, however the belief had already emerged centuries before. It was a behemoth of a belief which was unquestionably the most dominant in all sciences.
What is the relation of frequency to probability?
Bernoulli (also Borel) gave part of an answer in terms of "Laws of Large Numbers".Probabilities of single cases are essential in stating and proving the laws. Venn provided a thorough exposition of his staunch frequentist views in his treatise "The Logic of Chance: An Essay on the Foundations and Province of the Theory of Probability". Von Mises postulated kinds of infinite sequences that would typically(with probability 1) be produced by independent and identically distributed trials.
As carefully put by Diaconis, frequentism radically restricts the range of probability theory, and it must be judged inadequate as a general account of probability. So, whether Persi Diaconis was a frequentist or not will be left to the reader as an exercise to judge 😛 .But a deep question has been uncovered in the deellopment of the frequentist view: What is the nature of a random sequence?
Furthermore, What is the relation of idealization to reality? In frequentism, it arose because the development of a theory demanded more than actual frequencies in the world.It required limiting relative frequencies in idealized infinite sequences.
There is another question that the frequency view leaves hanging, that is, how probability can be a guide to life. To be more precise, how can probability as frequency inform degrees of belief and rational decision?
Venn answers this roughly that as degrees of belief in a single event, we should take the corresponding relative frequency in a series of like events.
So, again we trace back to our earlier question of equi-probable events or likely events. How can we define them without circularity?
Venn's flawed idealization of "likely" events
Venn claimed that if one's degrees of belief agree with the relative frequencies, then an infinite series of fair bets would have a payoff in the limit that is fair, and that is general, expected value could be identified with limiting average value.
He has no right to claim this. Consider an idealized sequence of coin flips with limiting relative frequency of heads = \( \frac{1}{2} \). Any bet at even odds is a fair bet. Consider an idealized agent A who bets on every toss and always loses. You might want to argue that this cannot happen, but there is in fact nothing a frequentist can do to preclude it.
However Venn was modest enough to see holes in his own theory. 😉
John Venn
Bernoulli and the WLLN
Jacob Bernoulli was well aware of the limitations of relying on intuitively equi-probable cases. He lookd towards frequency evidence to inform probability judgements, as practical men had always done formally.
He proved the first law of large numbers. With arbitrarily high probability, the relative frequency of heads can be made to approximate the probability of heads as closely as you please by choosing a long enough series of trials.
He aimed at a determination of the number of draws with replacement from an urn that would be required for the relative frequencies to be within specified bounds of the chances with a specified high probability.He remarks that if it were a question of frequencies exactly equaling the chances, a long series of trials would just make things worse. At this point, frequencies and chances are clearly treated as two distinct and separate things.
Bernoulli derived( with a tacit assumption of independence) an upper bound on the required number of trials. This was what he called his golden theorem. The law of large numbers follows.
Nevertheless, his bound was not very good and conjures up very large numbers of trials. Ars Conjectandi presents an instance:
The chance is \( \frac{3}{5} \), the desired interval for the relative frequency is between \( \frac{29}{50} \) and \( \frac{31}{50} \), and the desired probability that the frequency falls within that interval is \( \frac{1000}{1001} \). Bernoulli's bound says that this is achieved if the number of trials is at least 25,550.Datasets of this magnitude were not available at Bernoulli's time
Jacob Bernoulli
Bernoulli's Swindle
Bernoulli was quite into determination of chance from empirical data.He was well convinced that in many areas, it was impossible to determine chances by counting symmetric cases.An idea flashed through his mind that what we are not given to derive a priori , we at least can obtain a posteriori, that is, we can extract it from repeated observation of the results of similar examples.
The question is, given the data- the number of trials and the relative frequencies of success in those trials- what is the probability that the chances fall within a certain interval? It is evident that this is not the problem which Bernoulli solved.He called this problem the "inverse problem".
But, here comes the funny part; Bernoulli somehow convinced himself that he had solved the "inverse problem". Well how? It was by a vague argument using the concept of moral certainty. Bernoulli used this term to refer to a probability so close to 1 , that for all intents and purposes, one may treat it as a certainty. He argued that he had shown that with a large enough number of trials, it would be morally certain that relative frequency would be approximately equal to chance. But if frequency equals chance, then chance equals frequency.
What a slipup! Really motivational for those who make silly mistakes ... At least they don't publish them :P.
Thomas Bayes solved the "inverse problem" and this time there was no cheating.
Frequentism in recent times
Major contributors to frequentist statistics in the early 20th century included Fisher,Neyman and Pearson. Fisher contributed to most of statistics and made significance testing the core of experimental science; Neyman formulated confidence intervals and contributed heavily to sampling theory; Neyman and Pearson paired in the creation of hypothesis testing. All valued objectivity, so the best interpretation of probability available to them was frequentist. Fisher said, "...the theory of inverse probability is founded upon an error, and must be wholly rejected." (from his Statistical Methods for Research Workers). While Neyman was a pure frequentist, Fisher's views of probability were unique; Both had nuanced view of probability.
Lindley's Paradox
This is a major checkpoint in statistical history where the frequentists started to doubt themselves.
Lindley’s paradox is in fact a difficulty reconciling two paradigms — Bayesian and frequentist statistics. There is no mathematical inconsistency.
Let's look at an example : In a certain city 49,581 boys and 48,870 girls have been born over a certain time period. The observed proportion \(x \) of male births is thus \( \frac{49,581}{98,451} \approx 0.5036 \). We assume the number of male births is a binomial variable with parameter \( \theta \). We are interested in testing whether \( \theta \) is 0.5 or some other value. That is, our null hypothesis is \( H_0 : \theta = 0.5 \) and the alternative is \( H_1: \theta \neq 0.5 \).
A frequentist will approach the problem by computing a quantity called p-value .
Making a quite naive assumption that as the number of male births is quite large, we may assume normality of the fraction of male births \(X \sim N(\mu,\sigma^2) \) , where \( \mu=n \theta , \sigma^2 = n \theta (1- \theta) \)
We then calculate the quantity: \( P(X \ge x) \) taking the value of \( \mu \) in accordance to the null hypothesis.
We find that the so called p-value obtained is lower than \( \alpha=0.05 \).Thus, we reject \(H_0\). [This is just an empirical rule (quite questionable!!)]
A Bayesian on the other hand a Bayesian will use Bayes' Theorem:
Assuming no reason to favor one hypothesis over the other, the Bayesian approach would be to assign prior probabilities \( \pi(H_0)= \pi(H_1)=0.5 \).
Then he calculates \( P(H_0 | k) \) which is quite high (\( 0.95 \) ). This strongly favours \(H_0\) over \(H_1\).
Now, you decide , which among the two is the more realistic approach to this inference problem?
Can you show that this disagreement between the two approached becomes negligible as sample size increases?
This is the acid test of your inclination to either of the two approaches 🙂 .
Also, let me know if you are convinced whether p-values are misused everywhere or not. This is also a raging debate and it seems Bayesians tend to hate p-values too much :D.
More insight on the Bayesian approach will be provided by Uttaran in the consequent blog post..
Till then stay safe and enjoy learning!
References
1. Ten Great Ideas About Chance- Skyrms, Diaconis
2. A Treatise on Probability - John Maynard Keynes