Best algorithm to calculate Pi - Part1
Author: Kazi Abu Rousan
$\pi$ is not just a collection of random digits. $\pi$ is a journey; an experience; unless you try to see the natural poetry that exists in $\pi$, you will find it very difficult to learn.
Today we will see a python code to find the value of $\pi $ up to $1,00,000$ within $3$ to $4$ second. We will be using Chudnovsky Algorithm, which is one of the fastest method to calculate the value of $\pi $. Using this in 14th August, 2021 $62.8$ trillion digits of $\pi $ was calculated. Can you imagine this?
This is based on Ramanujan's $\pi $ formula and was discovered in $1988$. Let's see the formula and how we are going to use that.
Chudnovsky Algorithm
The value of $\pi $ is given by,
$$\frac{1}{\pi } = 12\sum_{k=0}^{\infty } \frac{(-1)^k (6k)! (545140134k + 13591409)}{(3k)! (k!)^3(640320)^{3k+\frac{3}{2}}}$$
For proof visit here: Proof
Let's just take the first term of this series and see what it gives us.

Just the first term is this much accurate. Just thinking about it surprises me.
So, how are we going to write the code?, well for this blog, we are directly going to use above expression. In some later blog, we will see how to make this much more efficient. We are doing so, to show you guys how powerful this method is.
Let's Code
Let's start our coding. Note one thing. Normally, when we perform this sort of algorithm, mostly the error comes from the fractional part. To reduce this error, we have to increase the precision of our calculation. For this we will be using a special python library.
There are many libraries which can help us in this. Some of them are;
- Decimal
- mpmath
- gmpy2
Our good old math library cannot do that as it mostly returns IEEE-$754$ $64$-bit result, which is roughly $17 $ digits only.
Here we will be using Decimal library.
Let's now begin our code:
import math as mp
from decimal import *
def pi_chudn(n):
getcontext().prec = n+50
k=0
pi_chud = 0
while k<n:
pi_chud+=(((Decimal(-1))**k ) * (Decimal(mp.factorial(6*k)))*(13591409 + 545140134*k))/Decimal((mp.factorial(3*k)*((mp.factorial(k))**3)*(640320**((3*k)+(Decimal(1.5))))))
k+=1
pi_chud = (Decimal(pi_chud) * 12)
pi_chud = (Decimal(pi_chud**(-1)))
return int(pi_chud*10**n)
exact_pi_val = str(31415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989)
for n in range(1,1000):
print(int(exact_pi_val[:n+1]))
print(pi_chudn(n))
is_true = (pi_chudn(n) == int(exact_pi_val[:n+1]))
print("for n = ",n, " It is ",is_true)
if is_true == False:
breakThis have run this program up to $413$ terms of $\pi $ and belief we, each and every digit was correct (most chudnovsky's programs you will find in internet gives wrong value after $14-15$ digit).
The string exact_pi_val contains $1001$ correct digit of $\pi $. So, The program will itself check if the calculated $\pi $ value is right or wrong up to $1000$ digit.
Although it's slow. To calculate $400$ digits of $\pi $, it needs $4.177294731140137$ sec.
We can plot the number of digits and calculation time.

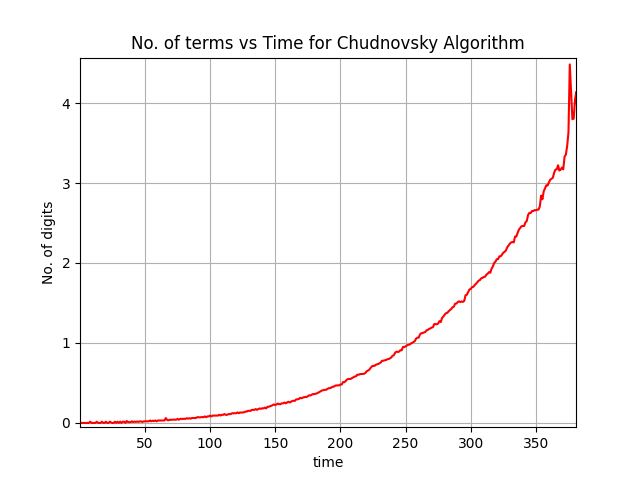
This is all for today. I have you have learnt something new.






